자연어처리(NLP)에서 트랜스포머 모델은 언어의 문맥과 의미를 깊이 이해할 수 있게 해주는 혁신적인 구조이다. 그 중심에는 어텐션 있으며, 특히 Self-Attention과 Multi-Head Attention이 있다.
Attention이란?
Aattention은 말 그대로 어디에 주의를 기울일 것인가를 계산하는 것이다.
쉽게 설명하면, 우리는 평범한 글을 읽을 때는 왼쪽에서 오른쪽으로 자연스럽게 읽어 내려가지만, 어려운 글을 읽을 때는 특정 단어나 문장에 집중하며 앞뒤 내용을 다시 확인하곤 한다. 이러한 집중과 상호참조의 과정을 딥러닝 모델에 반영하기 위한 연산 방식이 바로 어텐션이다.
Query, Key, Value
Attention은 Q(Query), K(Key), V(Value)라는 세 가지 개념을 사용한다.
- Query – 찾고자 하는 정보, 즉 ‘검색어’ 역할을 한다.
- Key – 데이터가 어떤 쿼리와 관련이 있는지를 판단할 수 있게 해주는 특징 값. 예를 들어 문서 검색에서는 키가 문서의 제목, 본문, 저자일 수 있다.
- Value – 관련 있는 데이터를 실제로 가져오는 값. 키를 통해 필터링된 후, 관련도에 따라 가중합되어 출력으로 사용됨.
Self-Attention
입력된 문장의 각 단어가 문장 내의 다른 단어들과 얼마나 관련이 있는지 계산하는 방식입니다. 입력된 문장의 모든 토큰을 Q, K, V로 변환한 뒤, 아래 그림과 같은 순서로 연산이 진행된다.
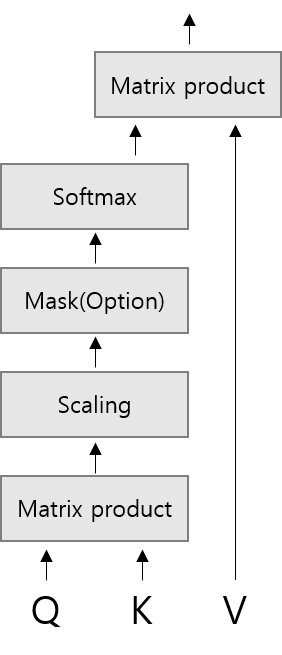
- Matrix product – Query와 Key의 내적해서 관련도를 측정한다.
- Sacling – 안정적인 학습을 위해 임베딩 차원수로 나눈다.
- Mask(Option) – Decoder 에서 미래의 토큰을 마스킹 할 것인지 선택하고 마스킹 적용.
- Softmax – 각 토큰 간 관련도 점수를 확률로 변환.
- Output – Value와 내적해서 최종 출력 생성.
Multi-head Attention
하나의 어텐션만 사용하는 것보다 여러 개의 어텐션을 병렬로 사용하면 더 다양한 관계를 동시에 파악할 수 있다.
단순히 하나의 Attention으로만 문장을 이해하면 놓치는 정보가 생길 수 있다.
그래서 여러 개의 head를 만들어서 서로 다른 방식으로 문장을 분석한 후, 그걸 합쳐서 더 풍부하고 정확한 표현을 얻는 방식이다.

- 입력을 여러 개의 Query, Key, Value를 head 크기로 분리하고 선형 변환을 한다.
- 각각의 헤드에서 Scaled Dot-Product Attention을 수행.
- 각 Attention 결과를 연결한다.
- 최종 선형 변환을 거쳐 결과 출력 한다.
셀프 어텐션과 멀티헤드 어텐션은 트랜스포머가 자연어의 의미를 효과적으로 이해하게 해주는 핵심 기술이다. 문장 내에서 중요한 단어들 간의 관계를 파악하고, 다양한 시각에서 이를 종합하는 능력을 부여한다.
