대규모 언어 모델(LLM)을 학습하거나 미세 조정할 때 가장 큰 제약 중 하나는 GPU 메모리 부족이다. 학습 과정에서 어떤 데이터가 메모리에 올라가는지, 이를 어떻게 줄일 수 있는지 정리해 보자.
GPU 메모리에 저장되는 주요 데이터
- Model Parameters
- 모델 가중치(Weight)와 편향(Bias) 등의 학습 가능한 값.
- 예를 들어 7B (7 Billion) 파라미터 모델의 경우 FP32 기준 약 28GB 메모리가 필요함.
- Gradient
- 각 파라미터에 대해 손실 함수의 기울기 값
- 역전파(Back propagation) 과정에서 계산되며, 파라미터와 같은 크기의 메모리를 필요로 함.
- Optimizer State
- Optimizer는 모델을 학습시키기 위해 파라미터를 업데이트 하는 알고리즘임. 이때 대부분의 고급 옵티마이저는 각 파라미터마다 추가적인 정보를 저장하는데 이 정보들이 Optimizer State임.
- 예를 들어 Adam 옵티마이저는 각 파라미터에 대해 1st moment (이전 기울기의 평균), 2nd moment (기울기 제곱의 평균) 추적 값을 저장함.
- 파라미터 크기의 2~3배에 달하는 추가 메모리 소모가 발생할 수 있음.
- Forward Activation
- 순전파(Forward pass)에서 중간 레이어의 출력값.
- 역전파 시 Gradient를 계산하기 위해 반드시 필요한 값.
- 가장 많은 메모리를 차지할 수 있음.
메모리 절약을 위한 전략
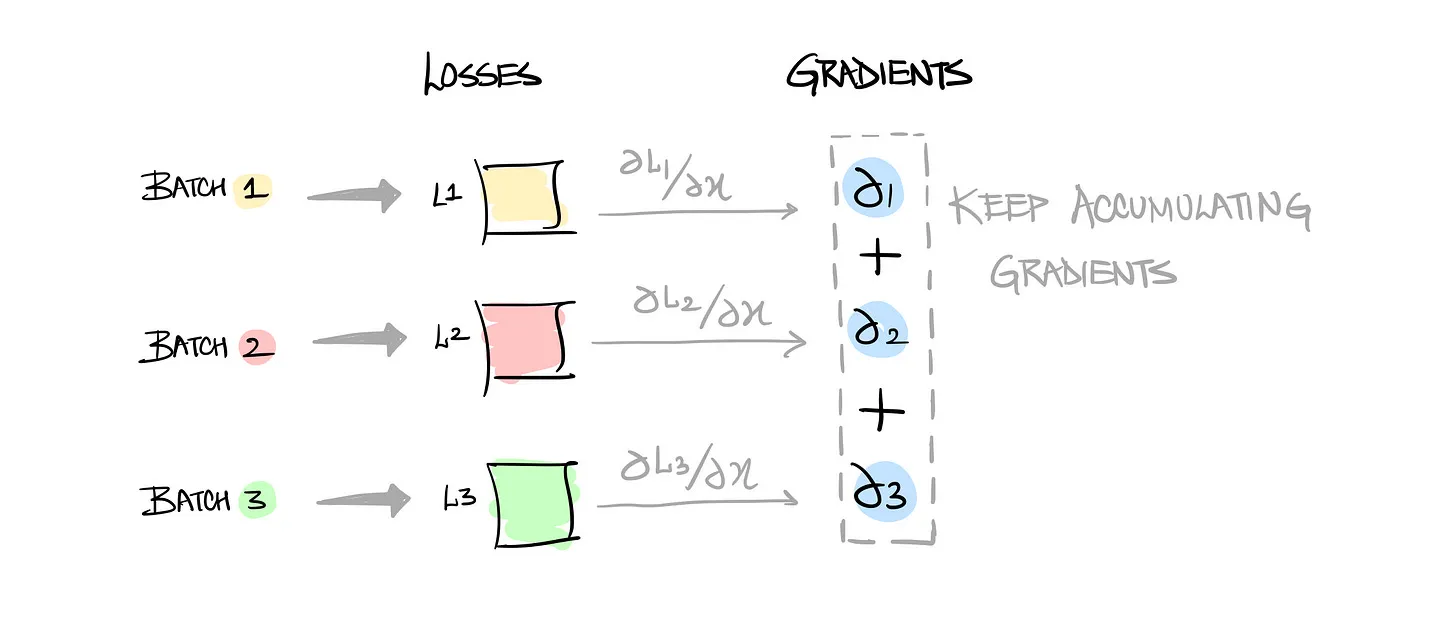
- Gradient Accumulation
- GPU 메모리 한계를 넘지 않기 위해 작은 배치(batch) 크기로 여러 번 계산하고 그래디언트를 누적(accumulate).
- 일정 스텝마다 누적된 그래디언트를 이용해 파라미터를 한 번 업데이트함.
- Batch size 16에서 OOM이 발생할 경우
-> Batch size 4 (gradient_accumulation_steps=4)로 설정.
-> Loss를 4로 나누어 누적하면 batch size 16과 동일한 학습 효과를 얻을 수 있음.
-> 실제 메모리 사용량은 Batch size 4로 계산 됨.
-> 작은 Batch size로 큰 Batch size로 학습로 학습한 것과 동일한 효과를 얻을 수 있지만 누적 연산을 추가로 해야 해서 학습 시간은 증가됨.
- Checkpointing (Activation Checkpointing)
- 순전파 시 전체 activation을 저장하지 않고, 마지막 출력값만 저장.
- 역전파 시 필요한 이전 상태는 다시 계산하여 사용.
- 순전파 상태 값을 모두 저장하지 않아서 메모리 사용량은 대폭 감소되지만, 역전파 시 순전파를 매번 반복 계산하므로 연산량 증가하여 학습 시간은 증가됨.
- Gradient Checkpointing
- 순전파의 일부 중간 지점(checkpoint)만 저장하고 나머지는 역전파 시 재계산.
- 전체를 저장하는 일반 방식과, 끝만 저장하는 기본 checkpointing의 중간 전략.
- 메모리 효율과 연산 효율을 적절히 절충한 방식이라 약간의 오버헤드는 존재하지만 일반적인 Checkpointing 보다는 효율적임.

GPU 메모리는 LLM 학습에서 가장 중요한 자원 중 하나이다. 위에서 소개한 전략들을 적절히 활용하면 제한된 자원 내에서도 효율적으로 모델을 학습시킬 수 있다.