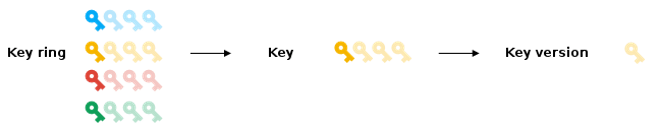프로덕션 환경에서 Azure Function App을 배포할 때, 앱의 상태를 확인하는 것은 매우 중요하다. 만약 Azure Function App의 상태가 ‘Runing’이 아니라면 배포가 되지 않는다.
Azure DevOps와 Azure CLI를 사용해 Function App의 상태를 확인하고, 앱이 실행 중이지 않다면 시작해야한다. 이 간단한 스크립트를 통해 배포 오류를 방지하고 원활한 운영을 보장할 수 있습니다.
Azure DevOps 작업 구성
- task: AzureCLI@2
inputs:
azureSubscription: ' Your Azure subscription details'
scriptType: 'bash'
scriptLocation: 'inlineScript'
inlineScript: |
state=$(az functionapp show --resource-group $(resourceGroupName) --name $(functionAppName) --slot second --query "state" -o tsv)
if [ "$state" != "Running" ]; then
echo "Function App is not running. Starting the Function App..."
az functionapp start --resource-group $(resourceGroupName) --name $(functionAppName) --slot second
else
echo "Function App is already running."
fi
여기까지 하면 db connection이 생성될 때 Always Encryed 설정이 활성화 된다. 하지만 CEK가 설정된 Table을 읽어 오지는 못한다. 제대로 값을 읽어 오기 위해서는 CEK Provider를 서비스 시작 시점에 설정을 해주어야 한다.
CEK Provider는 Program.cs에 다음과 같이 Provider를 구성해주면 된다.
var azureKeyVaultProvider = new SqlColumnEncryptionAzureKeyVaultProvider(new DefaultAzureCredential());
var dics = new Dictionary<string, SqlColumnEncryptionKeyStoreProvider>();
dics.Add(SqlColumnEncryptionAzureKeyVaultProvider.ProviderName, azureKeyVaultProvider);
SqlConnection.RegisterColumnEncryptionKeyStoreProviders(dics);
이제, 아래와 같이 간단히 앞서 암호화 했던 Users 테이블을 select해 보면 복호화 된 데이터를 확인 할 수 있다.
await using var conn = (SqlConnection)_context.Database.GetDbConnection();
await conn.OpenAsync();
await using var cmd = new SqlCommand("select * from Users", conn);
await using var reader = await cmd.ExecuteReaderAsync();
await reader.ReadAsync();
var result = $"{reader[0]}, {reader[1]}, {reader[2]}";
//id, email, name, registered date
//1, abc@gmail.com, abc, 2023-01-01 00:00.000
데이터를 저장 및 관리 하다 보면, 민감한 정보를 아무나 볼 수 없도록 식별 불가능하게 하도록 비식별화 작업을 해야 할 때가 있다.
데이터 비식별화를 하는 방법은 여러가지가 있지만, 그 중에서 데이터를 암호화하는 방법을 Azure SQL의 Always Encrypted 기능을 사용해서 구현해보려고 한다.
Always Encryted 기능은 Azure SQL에 저장된 민감한 데이터를 암호화 시킬 수 있고, 암호화에 사용된 암호화 키를 DB engine과 공유하지 않기 때문에 권한이 있는 클라이언트만 실제 데이터를 확인 할 수 있다. 그래서 권한에 따라서 데이터를 볼 수 있는 사람과 없는 사람을 명확히 구분할 수 가 있게 된다.
SQL Server Management Studio(SSMS)를 실행시킨다. Object Explore에서 DB Instance를 선택하고, Security 폴더로 이동한다. Always Encryted Key 폴더 밑에 Column master key폴더를 우클릭하여 master key 추가 메뉴를 클릭한다.
key store를 auzre keyvault를 선택하면, AAD Login을 해야한다. 정상적으로 로그인 하게 되면, subscription과 keyvault 리소스를 선택할 수 있다. 위에서 만든 RSA 키 정보를 찾아서 추가해준다.
여기까지 하면 Column master key가 생성된 것을 확인 할 수 있다.
Create CEK
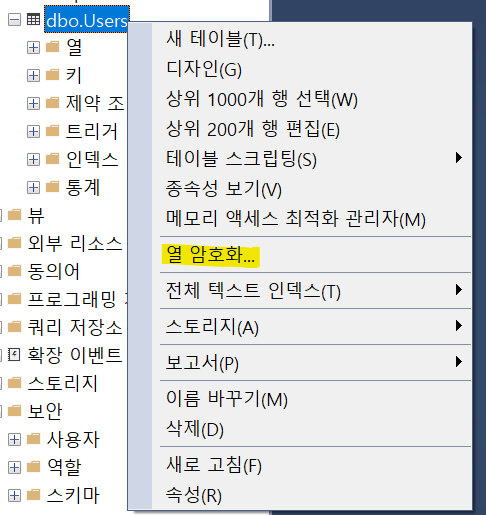
이제 암호화를 대상이 되는 테이블을 우클릭 하면 Column Encryption key를 추가할 수 있는 메뉴를 확인 할 수 있다.
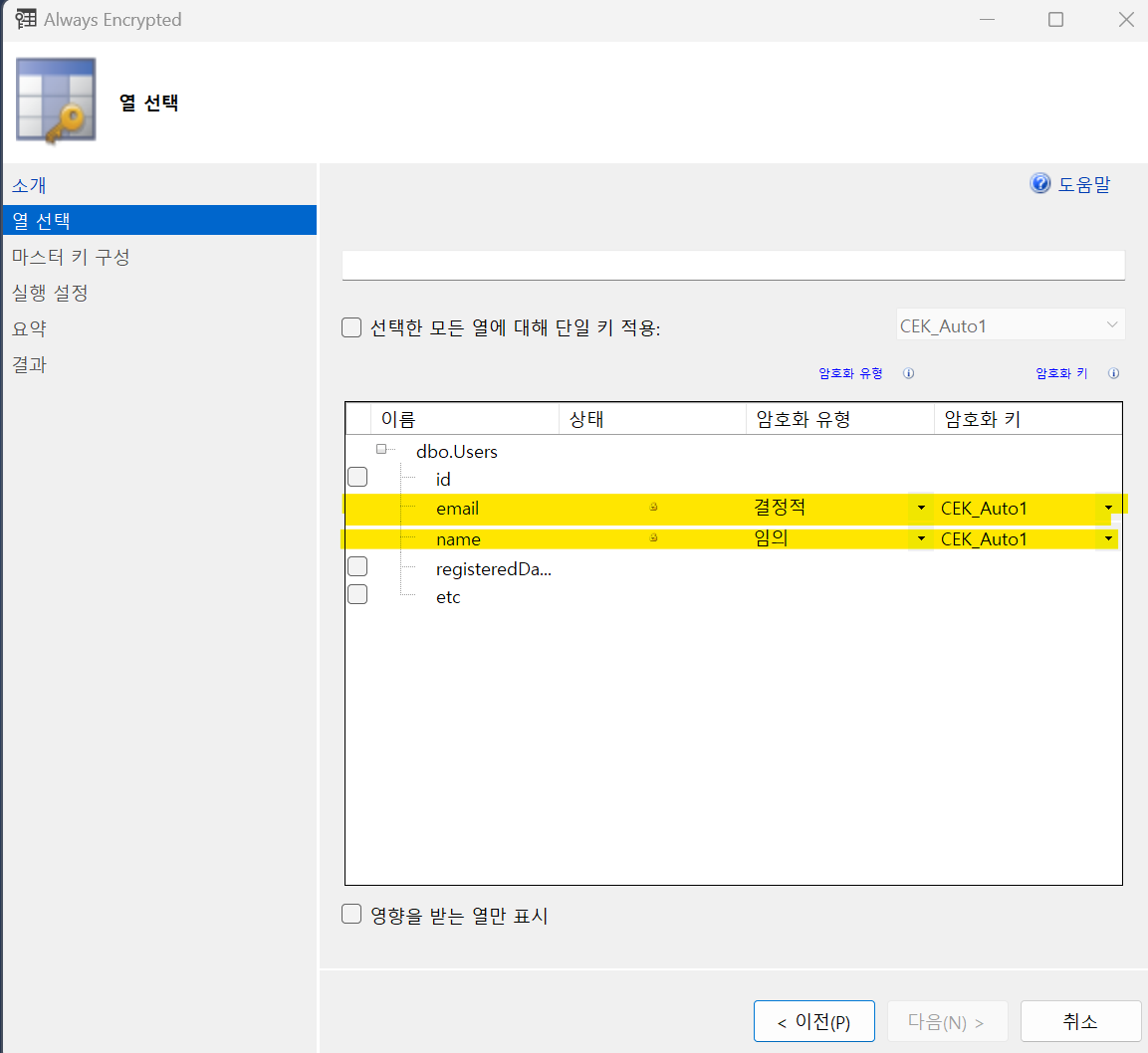
암호화를 해야 하는 Column들을 선택하고 위에서 만들 Master key를 사용해서 Column들을 암호화 한다.
이제 Table을 조회해 보면 해당 Column(email, name)의 정보가 식별할 수 없도록 암호화된 것을 확인 할 수 있다.
이 정보를 다시 복호화 하기 위해서는 SQL master 계정이나 Keyvault에 Cryptographic Operations 권한이 있는 계정을 사용해야 하며 Connection 정보에 “Column Encryption Setting = Enabled” 옵션을 추가해서 접근을 하면 복호화된 정보를 얻을 수 있다.
Azure SQL(이하 sql)의 data를 ElasticSearch(이하 es)로 검색을 하기 위해서 sql 데이터를 es의 index로 옮겨야 한다. 데이터를 옮기는 방법은 여러가지 방법이 있지만 일반적으로 많이 쓰이는 데이터 처리 오픈소스인 Logstash를 사용하여 옮기는 방법을 알아보자.
Logstash를 운영하는 방식도 다양하지만 간단하게 사용하려면 역시 K8S만 한 것이 없기 때문에 K8S에 구성해보자.
On-Prem이나 VM 형태로 사용하던 MSSQL Server를 Azure SQL로 Migration을 한다고 가정해보자. 기존에 사용하던 처리 성능에 맞춰 Cloud 상에 알맞은 수준의 리소스를 준비하고 옮겨야 할 것이다.
기존에 사용하던 SQL Server는 CPU와 Memory, Disk I/O등 Hardware적인 요소로 처리 성능을 나타낸다. 하지만 Azure SQL에서는 DTU(Database Throughput Unit)라는 단위를 사용하여 처리 성능을 나타내기 때문에 성능 비교가 쉽지가 않다.
DTU는 Hardware 성능 요소인 CPU, Disk I/O와 Database Log flush 발생양을 이용하여서 계산해낸 단위이다. 때문에 MSSQL Server에서 각 Metric들을 추출해 낼 수 있다면, DTU를 계산해 낼 수 있다. DTU 계산은 이미 Azure DTU Calculator라는 계산기가 제공되고 있기 때문에 추출해낸 Metric 값들을 설명대로 잘 넣어 주기만 하면 쉽게 확인해 볼 수 있다.
Metric을 추출하는 방법은 대상이 되는 SQL Server에서 DTU Calculator에서 제공하는 PowerShell Script를 관리자 권한으로 실행시켜 주기만 하면 된다. Script는 CPU, Disk I/O, Database Log flush에 대한 Metric들을 DTU Calculator에서 요구하는 형식으로 추출해준다. 때문에 일반적으로 On-Prem이나 VM 형태로 MSSQL Server를 사용하고 있다면, 계산해 내는데 별다른 어려움이 없을 것이다.
하지만 AWS RDS for MSSQL 같은 경우 MSSQL Server를 AWS에서 Cloud Service로 제공하기 위해 Wrapping한 서비스다보니 SQL Server에 대한 관리자 권한을 얻을 수가 없다. 이러한 이유 때문에 DTU Calculator에서 제공하는 PowerShell Script를 사용할 수 가 없다.
이런 경우, DTU 계산에 필요한 Metric들을 AWS에서 별도로 추출해야 한다. AWS에는 Cloudwatch라는 서비스를 제공하고 있는데, AWS 서비스들에 대한 Performance Metric을 기록하고 제공하는 역할을 한다.
Cloudwatch에서 metric을 추출하기 위해서는 AWS CLI를 사용하는 것이 편리하다. AWS Console의 우측 상단에 있는 CLI 실행 아이콘을 눌러 AWS CLI를 실행해 보자.
AWS CLI가 실행 되었다면, 아래 조회 명령어(list-metrics)를 실행시켜 제공되는 metric들에 대한 정보를 확인해 보자.
aws cloudwatch list-metrics --namespace AWS/RDS --dimensions Name=DBInstanceIdentifier,Value=[RDS for MSSQL Name]
잘 실행되었다면, cloudwatch에서 제공하는 Metric 리스트들을 확인 할 수 있다. 리스트 중 DTU계산에 필요한 CPU Processor Time과 Disk Reads/sec, Writes/sec에 값에 해당 하는 Metric 다음과 같다. (참고로, Log Bytes Flushed/sec에 해당하는 metric은 제공되지 않는다.)
생성한 csv 파일은 AWS CLI Storage에 저장 되어있다. 우측 상단의 Actions > Download File 메뉴를 사용하면 로컬 환경으로 다운 받을 수 있다.
3개의 파일 모두 다운 받아서 DTU 계산에 필요한 형식으로 맞춰준다.
% Processor Time = CPUUtilization
Disk Reads/sec = ReadIOPS
Disk Writes/sec = WriteIOPS
Log Bytes Flushed/sec에 해당하는 데이터가 없기때문에 0으로 넣어준다.
그림과 같은 형태로 구성될 것이다.
RDS for MSSQL metrics for DTU Calculator
이제, 한땀 한땀 준비한 데이터를 Azure DTU Calculator에 넣어 주기만 하면 되는데 한가지 주의할 점이 있다. 우리가 얻은 데이터는 RDS for MSSQL Server에 대한 정보이다. 때문에 여러 DB Instance에 대한 계산을 하는 Elastic Database 메뉴를 선택하여 계산 하도록 해야한다.
계산이 끝나면 아래와 같이 나오는데 이 결과를 통해서 AWS RDS에서 사용하던 성능 수준을 Azure SQL에서 그대로 사용하기 위해서 구성 해야하는 Service Tire/Performance Level을 확인 할 수 있다.
데브옵스(DevOps)는 소프트웨어의 개발(Development)과 운영(Operations)의 합성어로서, 소프트웨어 개발자와 정보기술 전문가 간의 소통, 협업 및 통합을 강조하는 개발 환경이나 문화를 말한다.
주로 아래 그림과 같이 개발과 운영간의 연속적인 사이클로 설명할 수 있다.
이를 통해서 얻는 장점은 다음과 같다.
신속한 제공
릴리스의 빈도와 속도를 개선하여 제품을 더 빠르게 혁신하고 향상할 수 있다. 새로운 기능의 릴리스와 버그 수정 속도가 빨라질수록 고객의 요구에 더 빠르게 대응할 수 있다.
안정성
최종 사용자에게 지속적으로 긍정적인 경험을 제공하는 한편 더욱 빠르게 안정적으로 제공할 수 있도록, 애플리케이션 업데이트와 인프라 변경의 품질을 보장할 수 있다.
협업 강화
개발자와 운영 팀은 긴밀하게 협력하고, 많은 책임을 공유할 수 있도록, 워크플로를 결합한다. 이를 통해 비효율성을 줄이고 시간을 절약할 할 수 있다.
보안
제어를 유지하고 규정을 준수하면서 신속하게 진행할 수 있다. 자동화된 규정 준수 정책, 세분화된 제어 및 구성 관리 기술을 사용할 수 있다.
그럼, DevOps를 실현하기 위해서는 어떻게 해야 하는가?
DevOps를 실현하기 위해서는 CI(Continuous Integration)/CD(Continuous Deployment(Delivery))라는 2가지 작업을 해야 한다.
CI(Continuous Integration)은 Development에 속하는 작업으로 지속적으로 프로젝트의 요구사항을 추적하며, 개발된 코드를 테스트 및 빌드를 수행한다.
프로젝트 기획 + 요구사항 추적
프로젝트 시작
기획(프로젝트 방법론 채택)
작업관리(Backlog 관리)
진행상황 추적
개발 + 테스트
코드작성
단위 테스트
소스제어
빌드
빌드 확인
CD(Continuous Deployment(Delivery))는 Operations에 속하는 작업으로 CI가 완료되어 빌드된 소스를 통합 테스트(개발, QA, Staging)를 거쳐 배포를 하며, 배포된 사항들을 지속적으로 모니터링하고 프로젝트 요구사항에 피드백하는 작업을 수행한다.
빌드 + 배포
자동화된 기능 테스트
통합 테스트 환경(Dev)
사전 제작 환경 (QA, Load testing)
스테이징 환경(Staging)
모니터링 + 피드백
모니터링
피드백
이제, DevOps를 하기위한 구체적인 작업을 알았으니, 실제 구성을 하도록 하는 제품들에 대해서 알아보자.
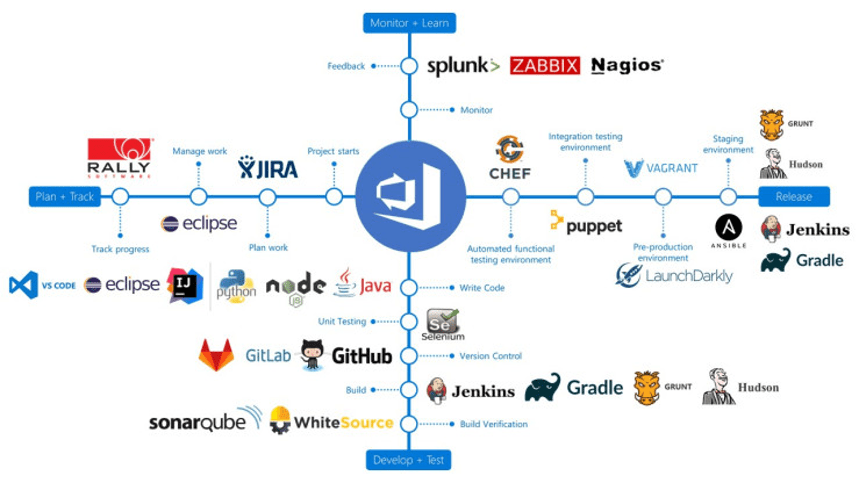
Azure DevOps vs Other Software
DevOps를 하기 위한 솔루션들은 이미 시중에 엄청나게 나와 있으며, 대게 오픈소스 형태로 많이 제공되고 있어서 바로 가져다 사용할 수 있다.
위 그림에서 볼 수 있듯이 DevOps의 각 단계에 맞추어서 원하는 (특화된)제품을 선택하여 사용하면 된다.
모든 단계를 빠짐 없이 구현한다고 가정하여, 예를 들면 다음과 같이 DevOps가 구현 될 수 있다.
Slack으로 요구사항 관리를 하고
Git으로 소스코드 관리를 하고
Maven으로 빌드를 하고
JUnit으로 테스트하고
Jenkins로 Docker에 배포하고
Kubernetes로 운영하며
Splunk로 모니터링 한다.
그런데 이런 경우, 벌써 필요한 제품에 8개나 된다. 프로젝트에 참여하는 모든인원이 이 제품들에 대해서 이해하고 사용하기 어려우며, 각 제품에대한 담당자들있어야 제대로 운영 될 수 있을 것이다. 게다가, 각기 다른 제품이라 다음 단계로 넘어가기 위한 추가적인 관리를 해야할 것이다.
이렇게 되면, 규모가 작은 곳에서는 몇가지 단계를 건너띄고 관리를 하게 되는데 이런 부분에서 예외사항이 생기기 시작하고, 결국 프로젝트 끝에서는 DevOps를 거의하지 못하는 상황이 생길 수 도있다.
반면, Azure DevOps는 하나의 DevOps 관리 솔루션을 제공한다. 때문에 Azure DevOps 하나만 사용해도 모든 절차를 구성 할 수 있다. 그리고 만약, 기존에 사용하던 제품이 있다 하더라도 아래 그림과 같이 3rd-party를 마이그레이션 혹은 연동 설정 할 수 있도록 하기 때문에 Azure DevOps 제품안에서 하나로 통합 관리 할 수 있다.
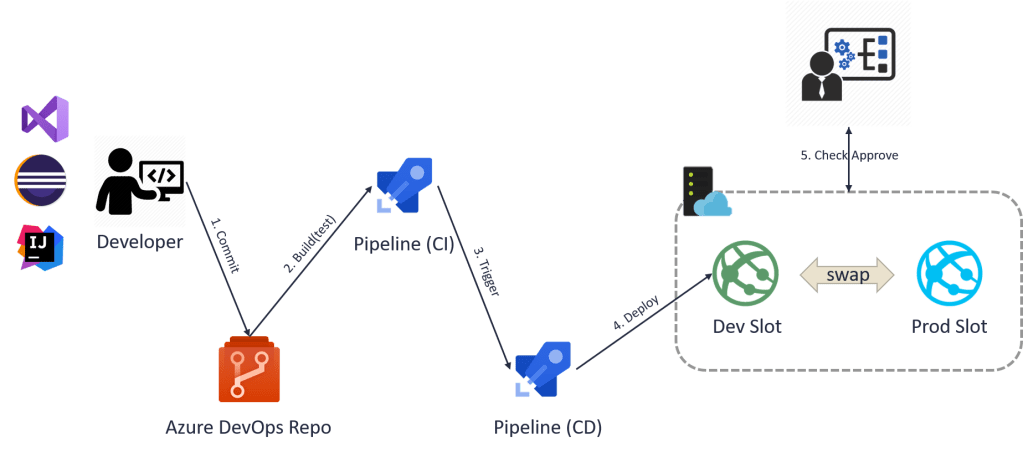
마지막으로, Azure DevOps를 사용하는 간단한 시나리오에 대해서 알아보자.
Azure DevOps에서는 파이프라인이라는 형태로 CI/CD를 구성하도록 되어 있으며, 각 단계 구성은 아래 그림과 같다.
Project (Agile) Board를 통해서 프로젝트 요구사항 추적 관리를 하고
Repo에서 각 Agile Board Task에 대한 소스코드 관리를 하고
소스가 커밋이 되면 CI 파이프라인을 통해 빌드 + 테스트를 수행하고
CI가 완료되면 Trigger 형태로 CD 파이프라인을 실행하고
CD 파이프라인을 통해 통합 테스트 + 배포를 하고
(옵션)담당자에게 최종 승인을 받고
운영 적용 및 모니터링을 한다.
Azure DevOps 이 외의 제품을 사용 했을 때와 단계는 거의 동일 하지만, 여기서 주목 할 점은 Azure DevOps 단일 제품에서 모두 제공 받고 구성 할 수 있다는 것이다.
(**여기서 다 설명 못한 부분이지만 CI/CD 과정 중에 Function(Trigger) 형태로 여러 기능들을 다양하게 엮을 수도 있다. 예를 들어 6번)
각각의 솔루션 전문가들이 있어서 운영한다면 문제가 없겠지만, DevOps를 처음 도입한다던가 규모가 작아 축소 운영을 해야하는 상황이라면 고려해 볼 수 있을 것 같다.
암호화 Key의 정확한 제어 엑세스 관리를 위해 Key ring, Key, Key version이라는 계층 구조를 가지고 있다.
Key ring
조직화 목적을 위해 키를 그룹화 한 것 이다.
Key는 Key를 포함하는 Key ring에서 권한을 상속받는다. 연관된 권한을 가진 Key를 Key ring으로 그룹화하면 각 키를 개벽적으로 작업을 수행할 필요 없이 Key ring 수준에서 해당 키를 대상으로 권한을 부여, 취소, 수정 할 수 있다.
Key
AES-256키를 GCM(Galois Counter Mode)로 사용한다.
특정한 용도를 위해 사용되는 암호화 키를 나타내는 명명된 객체이다.
시간이 경과 되어 새로운 키 버전이 생성되면 키자료인 암호화에 사용되는 실제 비트가 변경될 수 있음.
Key version
일정한 시점에 하나의 키와 관련된 키 자료를 나타낸다.
임의의 여러 버전이 존재 할 수 있으며 버전은 최소 하나 이상 있어야 한다.
Azure Key Vault
암호화 표준은 RSA-OAEP를 사용한다.
비밀정보를 중앙 위치에 보관하고 보안 액세스, 권한 제어 및 액세스 로깅을 제공한다.
비밀 정보를 접근하고 사용하려면 Key Vault에 인증 해야하며, Key Vault 인증은 AAD(Azure Active Directory)에서 인증 지원하는 ID(App Client ID)를 통해 인증 받을 수 있다.
접근 정책은 ‘작업’을 기반으로 한다. – Application 별로 비밀 값 읽기, 비밀 이름 나열, 비밀 만들기 등의 권한을 부여한다.
제공되는 보안 컨트롤
Data Protect – TDE(투명한 데이터 암호화)와 Azure Key Vault를 통합하면 TDE 보호기라는 고객 관리형 비대칭 키를 사용하여 DEK(데이터베이스 암호화 키)를 암호화할 수 있습니다.
Network ACL – 가상 네트워크 서비스 End-Point를 사용하면 지정된 가상 네트워크에 대한 액세스를 제한할 수 있습니다.
정리하면, AWS, GCP의 KMS는 암호화 키를 안전하게 저장 하는 것과 키를 암호화하는 작업(암호화와 복호화)에 초점이 맞춰져 있다고 볼 수 있고, 반면, Azure Key Vault는 백엔드에서는 키 암호화 작업을 통해 비밀을 저장하는 등, KMS와 유사하게 기능들을 제공하지만 그 외 추가 적인 관리 기능들을 제공하기 때문에 비밀 관리 솔루션을 제공한다고 볼 수 있다.