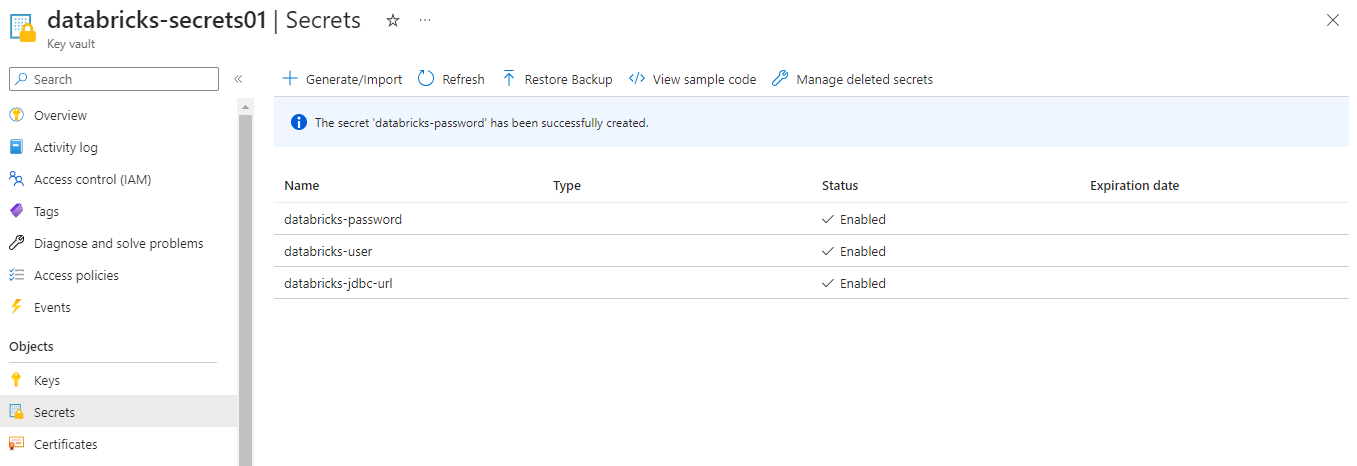
프로덕션 환경에서 Azure Function App을 배포할 때, 앱의 상태를 확인하는 것은 매우 중요하다. 만약 Azure Function App의 상태가 ‘Runing’이 아니라면 배포가 되지 않는다.
Azure DevOps와 Azure CLI를 사용해 Function App의 상태를 확인하고, 앱이 실행 중이지 않다면 시작해야한다. 이 간단한 스크립트를 통해 배포 오류를 방지하고 원활한 운영을 보장할 수 있습니다.
Azure DevOps 작업 구성
- task: AzureCLI@2
inputs:
azureSubscription: ' Your Azure subscription details'
scriptType: 'bash'
scriptLocation: 'inlineScript'
inlineScript: |
state=$(az functionapp show --resource-group $(resourceGroupName) --name $(functionAppName) --slot second --query "state" -o tsv)
if [ "$state" != "Running" ]; then
echo "Function App is not running. Starting the Function App..."
az functionapp start --resource-group $(resourceGroupName) --name $(functionAppName) --slot second
else
echo "Function App is already running."
fi
On-Prem이나 VM 형태로 사용하던 MSSQL Server를 Azure SQL로 Migration을 한다고 가정해보자. 기존에 사용하던 처리 성능에 맞춰 Cloud 상에 알맞은 수준의 리소스를 준비하고 옮겨야 할 것이다.
기존에 사용하던 SQL Server는 CPU와 Memory, Disk I/O등 Hardware적인 요소로 처리 성능을 나타낸다. 하지만 Azure SQL에서는 DTU(Database Throughput Unit)라는 단위를 사용하여 처리 성능을 나타내기 때문에 성능 비교가 쉽지가 않다.
DTU는 Hardware 성능 요소인 CPU, Disk I/O와 Database Log flush 발생양을 이용하여서 계산해낸 단위이다. 때문에 MSSQL Server에서 각 Metric들을 추출해 낼 수 있다면, DTU를 계산해 낼 수 있다. DTU 계산은 이미 Azure DTU Calculator라는 계산기가 제공되고 있기 때문에 추출해낸 Metric 값들을 설명대로 잘 넣어 주기만 하면 쉽게 확인해 볼 수 있다.
Metric을 추출하는 방법은 대상이 되는 SQL Server에서 DTU Calculator에서 제공하는 PowerShell Script를 관리자 권한으로 실행시켜 주기만 하면 된다. Script는 CPU, Disk I/O, Database Log flush에 대한 Metric들을 DTU Calculator에서 요구하는 형식으로 추출해준다. 때문에 일반적으로 On-Prem이나 VM 형태로 MSSQL Server를 사용하고 있다면, 계산해 내는데 별다른 어려움이 없을 것이다.
하지만 AWS RDS for MSSQL 같은 경우 MSSQL Server를 AWS에서 Cloud Service로 제공하기 위해 Wrapping한 서비스다보니 SQL Server에 대한 관리자 권한을 얻을 수가 없다. 이러한 이유 때문에 DTU Calculator에서 제공하는 PowerShell Script를 사용할 수 가 없다.
이런 경우, DTU 계산에 필요한 Metric들을 AWS에서 별도로 추출해야 한다. AWS에는 Cloudwatch라는 서비스를 제공하고 있는데, AWS 서비스들에 대한 Performance Metric을 기록하고 제공하는 역할을 한다.
Cloudwatch에서 metric을 추출하기 위해서는 AWS CLI를 사용하는 것이 편리하다. AWS Console의 우측 상단에 있는 CLI 실행 아이콘을 눌러 AWS CLI를 실행해 보자.
AWS CLI가 실행 되었다면, 아래 조회 명령어(list-metrics)를 실행시켜 제공되는 metric들에 대한 정보를 확인해 보자.
aws cloudwatch list-metrics --namespace AWS/RDS --dimensions Name=DBInstanceIdentifier,Value=[RDS for MSSQL Name]
잘 실행되었다면, cloudwatch에서 제공하는 Metric 리스트들을 확인 할 수 있다. 리스트 중 DTU계산에 필요한 CPU Processor Time과 Disk Reads/sec, Writes/sec에 값에 해당 하는 Metric 다음과 같다. (참고로, Log Bytes Flushed/sec에 해당하는 metric은 제공되지 않는다.)
생성한 csv 파일은 AWS CLI Storage에 저장 되어있다. 우측 상단의 Actions > Download File 메뉴를 사용하면 로컬 환경으로 다운 받을 수 있다.
3개의 파일 모두 다운 받아서 DTU 계산에 필요한 형식으로 맞춰준다.
% Processor Time = CPUUtilization
Disk Reads/sec = ReadIOPS
Disk Writes/sec = WriteIOPS
Log Bytes Flushed/sec에 해당하는 데이터가 없기때문에 0으로 넣어준다.
그림과 같은 형태로 구성될 것이다.
RDS for MSSQL metrics for DTU Calculator
이제, 한땀 한땀 준비한 데이터를 Azure DTU Calculator에 넣어 주기만 하면 되는데 한가지 주의할 점이 있다. 우리가 얻은 데이터는 RDS for MSSQL Server에 대한 정보이다. 때문에 여러 DB Instance에 대한 계산을 하는 Elastic Database 메뉴를 선택하여 계산 하도록 해야한다.
계산이 끝나면 아래와 같이 나오는데 이 결과를 통해서 AWS RDS에서 사용하던 성능 수준을 Azure SQL에서 그대로 사용하기 위해서 구성 해야하는 Service Tire/Performance Level을 확인 할 수 있다.