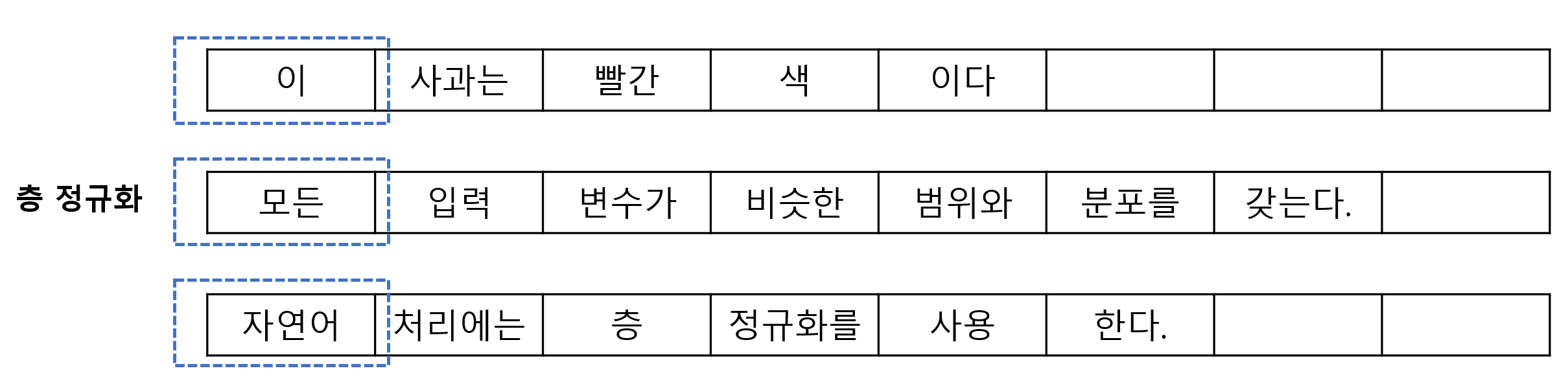
LLM은 수십억 개의 파라미터를 가지고 있기 때문에, 모든 파라미터를 학습시키는 Full Fine-Tuning 방식은 막대한 GPU 메모리와 시간이 필요하다. 특히 제한된 환경에서는 학습이 더 어려운데 이를 해결하기 위해 등장한 기법이 이를 해결하기 위해 등장한 기법이 PEFT(Parameter-Efficient Fine-Tuning)이다.
PEFT는 전체 파라미터를 학습하지 않고, 일부 파라미터만 학습하도록 하여 메모리 사용량과 연산량을 크게 줄인다. 그 결과, 학습 데이터가 적어도 효과적인 성능 향상을 기대할 수 있다.

LoRA (Low-Rank Adaptation)
LoRA는 모델의 기존 파라미터를 그대로 두고, 작은 보조 파라미터만 추가로 학습하는 방법이다. 기존의 Weight 행렬을 직접 업데이트하지 않고, 작은 두 개의 행렬 A, B를 학습하여 모델을 조정한다.
동작 원리
일반적인 선형 변환:

LoRA 적용 후:

- W: 기존 모델 파라미터(freeze)
- A, B: 학습할 작은 행렬
- r: 행렬의 랭크(rank), 매우 작게 설정 (low-rank)
이 방식을 사용하면 내부 구조 rank가 낮아, 학습해야 하는 파라미터 수가 매우 적어진다.
이해하기 쉽게 예를 들어 보면, 전체 파라미터가 1024 * 1024로 총 1,048,576개인 모델이 있다고 가정해보자. r을 8로 해서 LoRA를 적용하면, A와 B행렬 각각이 8,192개의 파라미터만 가지게 되고 두 개를 합쳐도 16,384개의 파라미터만 학습하면 된다. 이는 전체 파라미터의 약 1.6%에 불과하다. 100만개가 넘는 파라미터 전부를 학습하는 대신 극히 일부만 학습해도 전부를 학습한것과 비슷한 학습 효과를 볼 수 있다.
QLoRA (Quantized LoRA)
QLoRA는 LoRA에 양자화(Quantization) 를 적용한 방식이다. 기존의 float32 파라미터를 int4와 같이 작은 비트수로 압축하여 GPU 메모리를 크게 절약한다.
특징
- 최대 4배 이상 GPU 메모리 사용량을 감소할 수 있음.
- 모델 본체는 작아지지만, optimizer state는 여전히 저장해야 하므로 경우에 따라 더 많은 메모리가 필요할 수 있음.
- optimizer state는 전부 GPU에 올리지 않고, 필요할 때만 GPU로 이동하여 학습 하고 사용하지 않을 때는 CPU 메모리에 올려두도록 해야함.