대형 언어 모델(LLM)에서 Encoder와 Decoder는 Transformer 구조의 두 핵심 구성 요소이다. 두 모듈은 서로 다른 역할과 구조적 특징을 가지고 있으며, 자연어 처리에서 입력을 이해하고 출력을 생성하는 데 중요한 역할을 한다.

Encoder
인코더는 입력 데이터를 처리하여 의미를 압축하고, 모델이 이해할 수 있는 벡터 표현으로 변환하는 역할을 한다.
구조적으로 Multi-Head Attention, Layer Normalization, Feed Forward Layer가 반복적으로 쌓인 형태다.
Encoder의 각 층 사이에는 Residual Connection이 있어, 입력 값을 변환 결과에 다시 더해 안정적인 학습이 가능하게 한다. Residual Connection은 깊은 네트워크에서 정보 손실을 방지하고, Vanishing Gradient 문제를 완화 한다.
입력 텍스트의 전후 관계를 이해하고, Context을 반영한 Embedding을 생성하고, 이 결과를 Decoder의 Cross Attention단계에서 활용할 수 있게 한다.
Decoder
디코더는 인코더의 출력을 바탕으로 최종적으로 텍스트를 생성하는 역할을 한다.
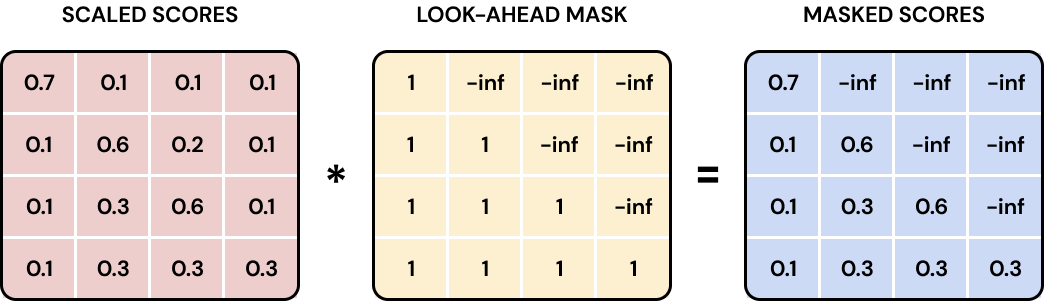
구조적으로는 Encoder와 다르게 Multi-Head Attention대신 Masked Multi-Head Attention을 사용한다.
Cross Attention Layer를 통해서 Encoder의 결과를 입력으로 받아 사용한다.
토큰을 생성할 때, 사람의 글쓰기처엄 순차적으로 토큰을 하나씩 생성한다. 이미 생성된 토큰을 기반으로 다음 토큰을 예측한다.
학습할 때는 모두 완성된 텍스트를 입력 받는데 이 어텐션을 그대로 활용하는 경우 미래시점에 작성해야하는 텍스트를 미리 확인하게 되는 문제가 생긴다. 이런 문제를 막기위해 Masking을 적용한다.