딥러닝 모델을 학습할 때, 정규화(Normalization)는 빠르고 안정적인 학습을 위한 핵심 기법 중 하나다. 특히 자연어 처리(NLP)에서 사용되는 트랜스포머 기반 LLM(Large Language Model)에서는 층 정규화(Layer Normalization)가 중요한 역할을 한다.
정규화는 딥러닝 모델에서 입력 데이터가 일정한 분포(평균과 분산)를 갖도록 조정해주는 기법이다. 정규화를 통해 모델은 다음과 같은 이점을 얻을 수 있다
- 학습이 더 안정적이고 빠르게 진행 됨.
- 과적합(Overfitting)방지에 도움 됨.
- DNN(Deep neural network) architecture에서도 정보 흐름이 원활 함.
Batch Normalization VS Layer Normalization
Batch Normalization
배치 정규화는 입력 데이터를 배치 단위로 묶어서 평균과 분산을 계산하고 정규화한다. 주로 이미지 처리 분야에서 사용되며, 자연어 처리에서는 아래 이미지 처럼 문장마다 길이가 다르더라도 일정한 길이로 맞추기 위해 PAD 토큰이 삽입된다.

배치 마다 구성데이터가 달라서 정규화 효과가 일정하지 않게 되서 LLM에서는 일반적으로 Bath Norm을 사용하지 않는다.
Layer Normalization
층 정규화는 각 샘플(토큰 임베딩)마다 독립적으로 정규화한다. 같은 문장 안의 각 단어 벡터를 기준으로 평균과 분산을 계산한다.
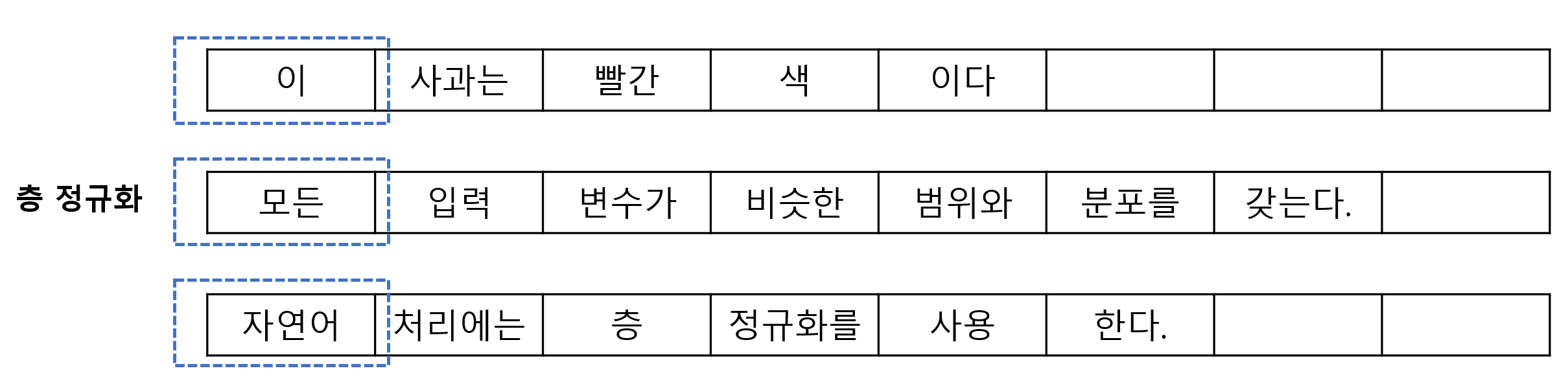
토큰 임베딩별 정규화를 수행하기 때문에 문장의 길이에 영향을 받지 않고 정규화를 동일하게 적용할 수 있다.
LLM과 같은 트랜스포머 기반 자연어 처리 모델에서는, 입력의 다양성과 길이의 불균형을 고려해 배치 정규화 대신 층 정규화를 사용한다. 이는 모델이 더 빠르고 안정적으로 학습될 수 있도록 돕고, 문맥 이해 능력을 향상시키는 중요한 기법이다.
