Elasticsearch를 쓰다 보면 Index document에 대량으로 새로운 필드를 추가해야 하는 상황이 생긴다.
update-by-query나 bulk update를 시도하기엔 문서 수가 너무 많거나, 문서 하나하나를 업데이트해야 해서 작업 비용이 커지는 경우도 있다.
이런 문제를 해결하기 위해 선택한 기능이 바로 Enrich Processor이다.
Enrich를 사용하면 문서를 인덱싱하는 시점에 다른 인덱스의 참조 데이터를 자동으로 병합할 수 있어서, 복잡한 업데이트 작업 없이 깔끔하게 데이터를 보강할 수 있다.
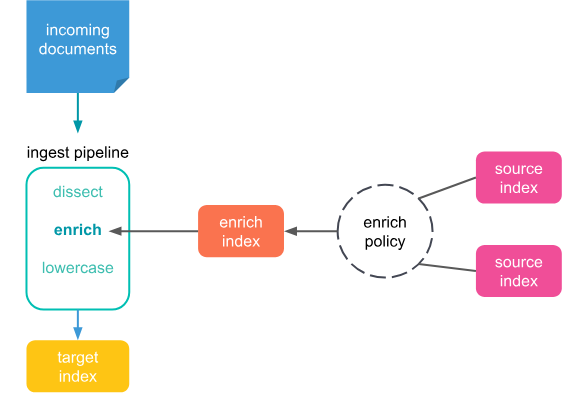
Enrich란?
Enrich Processor는 인덱싱 과정에서 들어오는 문서를 대상으로, 미리 준비된 참조 데이터(reference data) 를 자동으로 붙이는 기능이다. 한마디로 “문서 저장 전에 실시간 lookup + 자동 join” 을 수행하는 구조이다.
Enrich 기능은 다음 3가지 요소로 구성된다.
| Source Index | 참조 데이터가 들어 있는 인덱스 (예: 제품 정보, 사용자 정보) |
| Enrich Policy | 어떤 필드로 매칭하고 어떤 필드를 보강할지 정의 |
| Enrich Index | Policy 실행 시 생성되는 최적화된 시스템 인덱스 (.enrich-*) |
Enrich Processor는 매번 검색을 수행하지 않고, 정적·최적화된 enrich index를 조회하기 때문에 성능 손실 없이 빠르게 보강 작업을 수행한다.
동작 예시
사용자의 이메일을 기반으로 해당 사용자의 기본 정보를 문서에 자동 보강하는 상황을 살펴본다.
1) Source Index 준비
PUT users/_doc/1?refresh=wait_for
{
"email": "alice@example.com",
"first_name": "Alice",
"city": "Seoul"
}
2) Enrich Policy 생성
PUT /_enrich/policy/user-policy
{
"match": {
"indices": "users",
"match_field": "email",
"enrich_fields": ["first_name", "city"]
}
}
3) Enrich Policy 실행 → enrich index 생성
POST /_enrich/policy/user-policy/_execute
여기까지 수행하면 .enrich-user-policy-* 형태의 전용 인덱스가 생성된다.
4) Ingest Pipeline 생성
PUT /_ingest/pipeline/user_lookup
{
"processors": [
{
"enrich": {
"policy_name": "user-policy",
"field": "email",
"target_field": "user_info",
"max_matches": 1
}
}
]
}
5) 문서 인덱싱
PUT /logs/_doc/1?pipeline=user_lookup
{
"email": "alice@example.com"
}
// 결과
{
"email": "alice@example.com",
"user_info": {
"first_name": "Alice",
"city": "Seoul"
}
}
문서가 인덱싱될 때 자동으로 참조 데이터가 붙는 구조다.
update-by-query 없이 “인덱싱 순간에 데이터가 완성되는” 형태라고 보면 된다.
제한사항
❗ 자주 변경되는 참조 데이터를 Enrich로 처리하는 경우
Enrich Processor는 source index를 직접 조회하지 않고 Enrich Index를 조회하는 구조이다. 따라서 참조 데이터가 변경되면 enrich index를 재생성하는 작업을 반복하게 된다.
참조 데이터가 자주 바뀐다면 재생성 작업을 반복해야 하고, 그만큼 시스템 부하도 증가한다.
특히 대규모 인덱스에서는 재생성 비용이 커져 전체 ingest 성능에 영향을 줄 수 있다.
따라서 Enrich는 자주 변하지 않는 데이터인 경우에 사용하는 것이 적합하다.