대규모 언어 모델(LLM, Large Language Model)의 학습은 수십억 개 이상의 파라미터를 다루기 때문에, 단일 GPU의 메모리나 연산 능력으로는 처리하기 어렵다. 이러한 문제를 해결하기 위해 병렬화(parallelism) 전략이 도입되며, 주로 두 가지 방식인 모델 병렬화(Model Parallelism) 와 데이터 병렬화(Data Parallelism)가 사용된다.
Model Parallelism
모델 병렬화는 하나의 모델을 여러 GPU에 분산시켜 학습하는 방식입니다. 모델이 너무 커서 단일 GPU 메모리에 올릴 수 없을 때 사용된다. 대표적인 두 가지 방식이 있다.
- Pipeline Parallelism
- 딥러닝 모델의 층(Layer) 단위로 모델을 분할하고, 각 분할을 다른 GPU에 할당한다.
- 입력 데이터가 GPU를 순차적으로 통과하며 forward/backward 연산이 수행된다.
- 모델 크기를 효과 적으로 분산 할 수 있지만, 각 GPU가 순차적으로 동작하게 되어서 파이프라인 버블 문제가 생길 수 있다.
- 그림에서 머신을 1, 2와 3, 4로 나누면 파이프라인 병렬화이다.
- Tensor Parallelism
- 하나의 층 내부에서 계산되는 텐서 연산을 여러 GPU에 나누어 수행한다.
- 행렬 곱 연산에서 행 또는 열을 나눠 병렬 연산 후 결과를 합치는 연산을 하면서 수행된다.
- 레이어 수준보다 더 미세하게 병렬화할 수 있어서 계산량을 세밀하게 분산이 가능하지만, GPU간 통신이 빈번하게 발생하게 되어 통신 오버헤드가 커질 수 있음.
- 그림에서 머신을 1, 3과 2, 4로 나누면 텐서 병렬화이다.

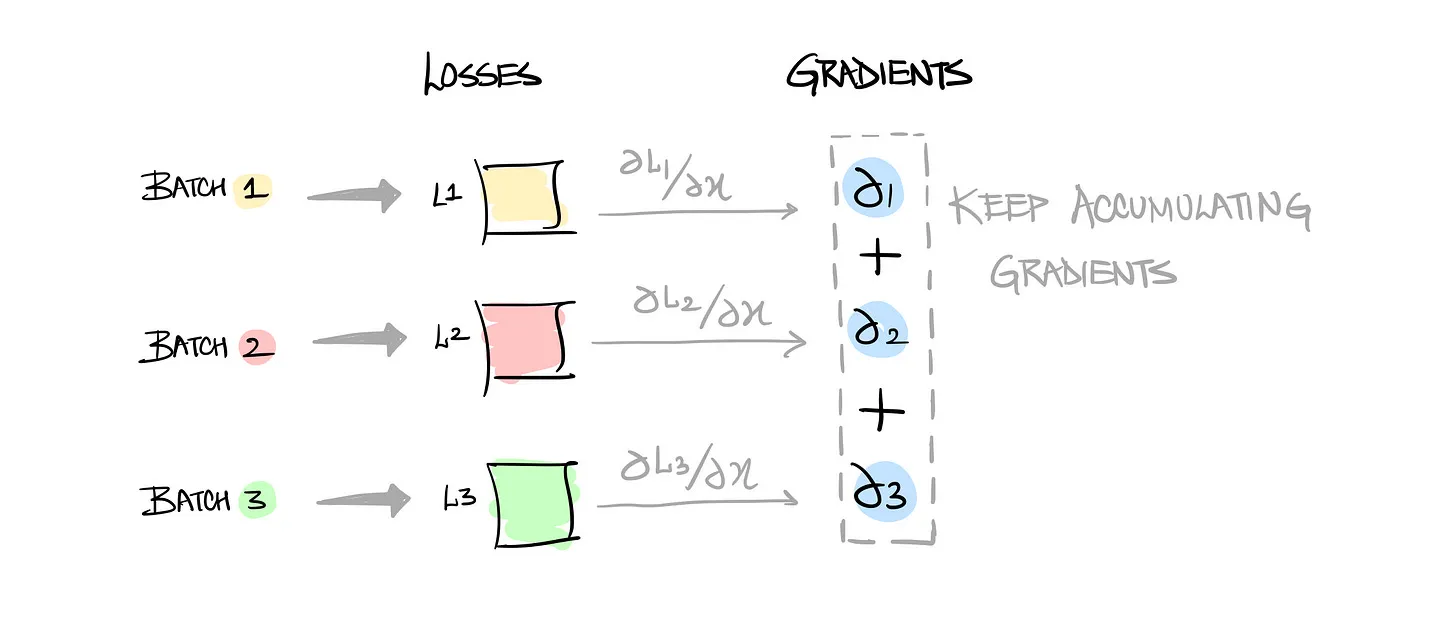
Data Parallelism
모델 크기가 하나의 GPU에 올라가기 적당하고 데이터가 많을 경우 사용할 수 있는 방식으로 데 모델을 그대로 복제한 후, 서로 다른 GPU에서 다른 데이터를 학습시키는 방식이다.
그림 처럼 각 GPU는 동일한 모델을 가지고 있으며, 각기 다른 미니배치 데이터를 학습한다.

forward/backward 연산 후, 파라미터의 그레이디언트(gradient) 를 모든 GPU가 서로 동기화하여 업데이트한다.
구현이 간단하고 대부분의 프레임워크에서 지원이 되지만, 모델 크기가 GPU 메모리에 들어가야 하고, 모든 GPU 간의 gradient 통신 비용이 크다.
LLM 모델 학습은 단순히 모델을 만드는 것 이상으로 효율적인 리소스 분산이 핵심이다. 모델 크기, 하드웨어 환경, 통신 병목 등을 고려하여 파이프라인 병렬화, 텐서 병렬화, 데이터 병렬화를 적절히 조합여 사용해야 한다.