Databricks에서 작업을 할 때 외부 데이터 소스를 가져와야 할 때가 있다. 이럴 때 외부 데이터 에 접근하기 위해서 연결 정보( ID, Password 등)가 필요하게 되는데, 이 정보는 작업자 외에 유출되면 안되는 경우가 있다.
이런 유출에 민감한 정보를 다뤄야 할 때, Secret manager 서비스를 사용하면 좋고, 이번 포스트에서는 Azure에서 제공하는 Key Vault 서비스를 사용해서 Databricks에서 민감정보를 다루는 방법을 알아보겠다.
먼저, Azure Key Vault 리소스를 생성하고 Secret에 연결 정보(SQL Connection string)를 등록한다.
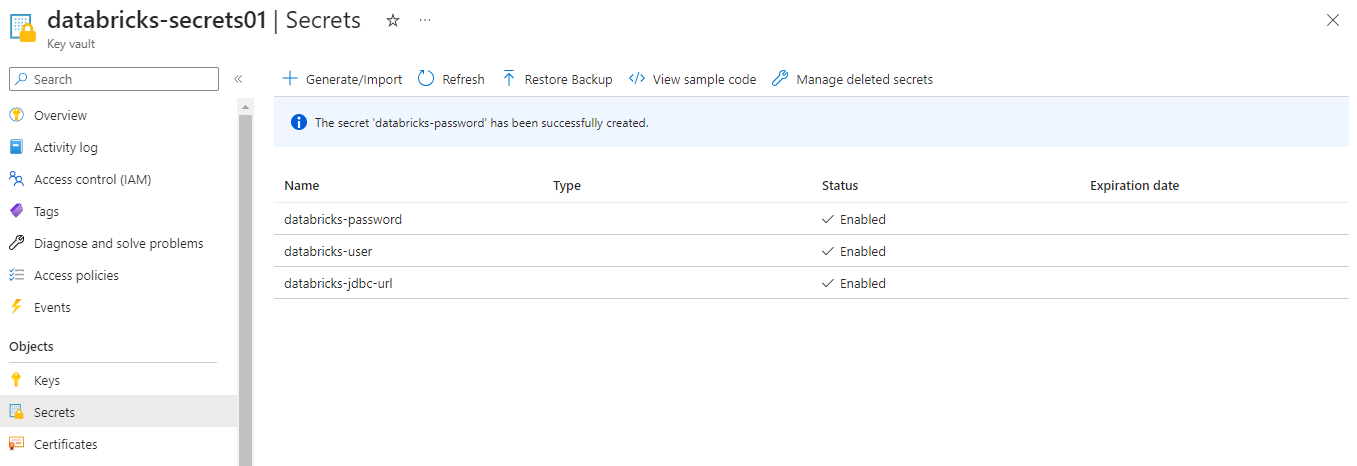
이제 Databricks에서 Key Vault에 등록된 정보를 사용하기 위해서 secret scope를 만든다.
databricks secrets create-scope --scope databricks-secrets01 --scope-backend-type AZURE_KEYVAULT --resource-id /subscriptions/<subscription Id>/resourceGroups/<resource group name>/providers/Microsoft.KeyVault/vaults/databricks-secrets01 --dns-name https://databricks-secrets01.vault.azure.net/
잘 만들어 졌는지 아래 scope list 명령어로 확인해 본다.
databricks secrets list-scopes
Scope Backend KeyVault URL
-------------------- -------------- ---------------------------------------------
databricks-secrets01 AZURE_KEYVAULT https://databricks-secrets01.vault.azure.net/
이제 Databricks에서 Key Vault에 등록된 Secret 값을 사용하기 위한 준비 작업은 끝났다.
Workspace에서 notebook을 하나 만들고 아래 script 처럼 secret 값을 불러와 사용해보자.
jdbcUrl = dbutils.secrets.get(scope="databricks-secrets01", key="databricks-jdbc-url")
connectionProperties = {
"user": dbutils.secrets.get(scope="databricks-secrets01", key="databricks-user"),
"password": dbutils.secrets.get(scope="databricks-secrets01", key="databricks-password")
}
위 방식대로 불러온 값들은 변수에 저장되지만 databricks 내에서는 확인 할 수 없다.

값을 확인하기 위해서 print를 해보면 “REDACTED”라고 출력되는 것을 확인 할 수 있다.
하지만 해당 변수를 이용해서 실행시켜보면 정상 동작한다.
df = spark.read.jdbc(url=jdbcUrl, table='sys.objects', properties=connectionProperties)
df.show(2)
+----------+---------+------------+---------+----------------+----+------------+--------------------+--------------------+-------------+------------+-------------------+
| name|object_id|principal_id|schema_id|parent_object_id|type| type_desc| create_date| modify_date|is_ms_shipped|is_published|is_schema_published|
+----------+---------+------------+---------+----------------+----+------------+--------------------+--------------------+-------------+------------+-------------------+
| sysrscols| 3| null| 4| 0| S |SYSTEM_TABLE|2023-03-30 17:00:...|2023-03-30 17:00:...| true| false| false|
|sysrowsets| 5| null| 4| 0| S |SYSTEM_TABLE|2009-04-13 12:59:...|2023-03-30 17:00:...| true| false| false|
+----------+---------+------------+---------+----------------+----+------------+--------------------+--------------------+-------------+------------+-------------------+
이렇게 Azure Key Vault를 이용하면 Databricks에서 민감정보를 다뤄야 할 때, 실제 값을 보여주지 않으면서 script는 정상 동작 시킬 수 있다.
마지막으로, 사용하는 key vault에 있는 민감정보 값들이 더 이상 필요 없어진다면 해당 key vault에 접근 할 수 없도록 하는 것이 바람직하다. delete scope로 더 이상 사용 할 수 없도록 scope를 제거 할 수 있다.
databricks secrets delete-scope --scope databricks-secrets01