최근 프로젝트에서 텍스트/이미지 임베딩을 .NET 환경에서 직접 활용할 방법을 찾아보다가, TransformersSharp라는 프로젝트를 발견했다. 이 라이브러리는 Hugging Face의 transformers Python 라이브러리를 C#에서 직접 호출할 수 있도록 wrapping한 형태다. 덕분에 별도의 Python 서버를 띄우고 REST API를 붙이지 않아도 .NET 코드 안에서 곧바로 모델을 다룰 수 있다.
TransformersSharp는 기본적으로 텍스트 기반 임베딩과 파이프라인 기능들을 제공한다. 예를 들어 SentenceTransformer를 통해 문장을 벡터화할 수 있지만 이미지를 벡터화 할 수는 없다.
그래서 직접 TransformersSharp를 fork(Link)해서 기능을 다음과 같이 확장했다.
Python Wrapper
sentence_transformers_wrapper.py에 다음 함수를 추가했다.
def load_image(url_or_path):
if url_or_path.startswith("http://") or url_or_path.startswith("https://"):
return Image.open(requests.get(url_or_path, stream=True).raw)
else:
return Image.open(url_or_path)
def encode_image(model: SentenceTransformer, image_path: str) -> Buffer:
"""
Encode an image using the SentenceTransformer model.
"""
image = load_image(image_path)
return model.encode(image)
C# Wrapper
SentenceTransformer.cs에는 다음 메서드를 추가했다.
public float[] GenerateImage(string image_path)
{
var result = TransformerEnvironment.SentenceTransformersWrapper
.EncodeImage(transformerObject, image_path);
return result.AsFloatReadOnlySpan().ToArray();
}
이제 텍스트와 이미지를 같은 환경에서 임베딩할 수 있다.
using Microsoft.Extensions.AI;
using TransformersSharp;
var transformer_text = SentenceTransformer.FromModel(
"sentence-transformers/clip-ViT-B-32-multilingual-v1",
trustRemoteCode: true);
var transformer_image = SentenceTransformer.FromModel(
"clip-ViT-B-32",
trustRemoteCode: true);
var text_embeddings = transformer_text.GenerateSentence("A dog in the snow");
var image_embeddings = transformer_image.GenerateImage(
"https://images.unsplash.com/photo-1547494912-c69d3ad40e7f?...");
Console.WriteLine($"Text Vector: {string.Join(", ", text_embeddings.Take(10))}...");
Console.WriteLine($"Image Vector: {string.Join(", ", image_embeddings.Take(10))}...");
Python 서버 없이도 .NET 안에서 바로 모델을 다룰 수 있다는 점이 굉장히 편리한 부분이 있었다. TransformersSharp 자체는 아직 완성도가 높은 수준은 아니지만, 필요한 기능을 확장할 수 있어서 오히려 테스트 해보기 좋았다.
Jupyter notebook을 기본값으로 사용하다 보면 Python만 사용할 수 있게 되는 경우가 있다. 이런 경우 R programming으로 작업한 내용을 보려고 하면, R studio 등 별도의 Tool로 작업 내용을 열어 봐야 한다. 그런데 이렇게 여러개의 툴을 쓴다는게 번거롭고 귀찮을 수 있다.
이런 수고로움을 조금이나마 줄이기 위해서 Jupyter notebook에서 R을 실행하는 방법을 알아보겠다.
먼저, 터미널에서 대상이 되는 Jupyter notebook이 설치된 가상환경을 활성화 한다.
가상환경이 활성화된 터미널
다음으로 아래 명령문을 실행 시켜주면 Jupyter notebook에 R 패키지가 설치 된다.
# R 실행
$ R
# IRkernel 패키지 설치
$ install.packages(‘IRkernel’)
# 커널 설치 확인
$ IRkernel::installspec()
# Jupyter notebook 실행
$ jupyter notebook
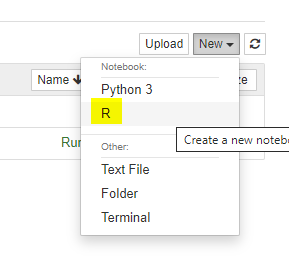
실행된 Jupyter notebook에 접속하여 “New”버튼을 눌러 확인해보자. 다음과 같이 R programming을 할 수 있는 R Notebook을 생성할 수 있을 것이다.
출력 결과를 알아보기 쉽게 한글로 표현하기 위해서는 settings.py에 출력결과가 utf-8로 인코딩될 수 있도록 설정을 추가 해주면 된다.
FEED_EXPORT_ENCODING = 'utf-8'
설정 내용을 저장하고 다시한번 newsBot을 실행 시켜보자.
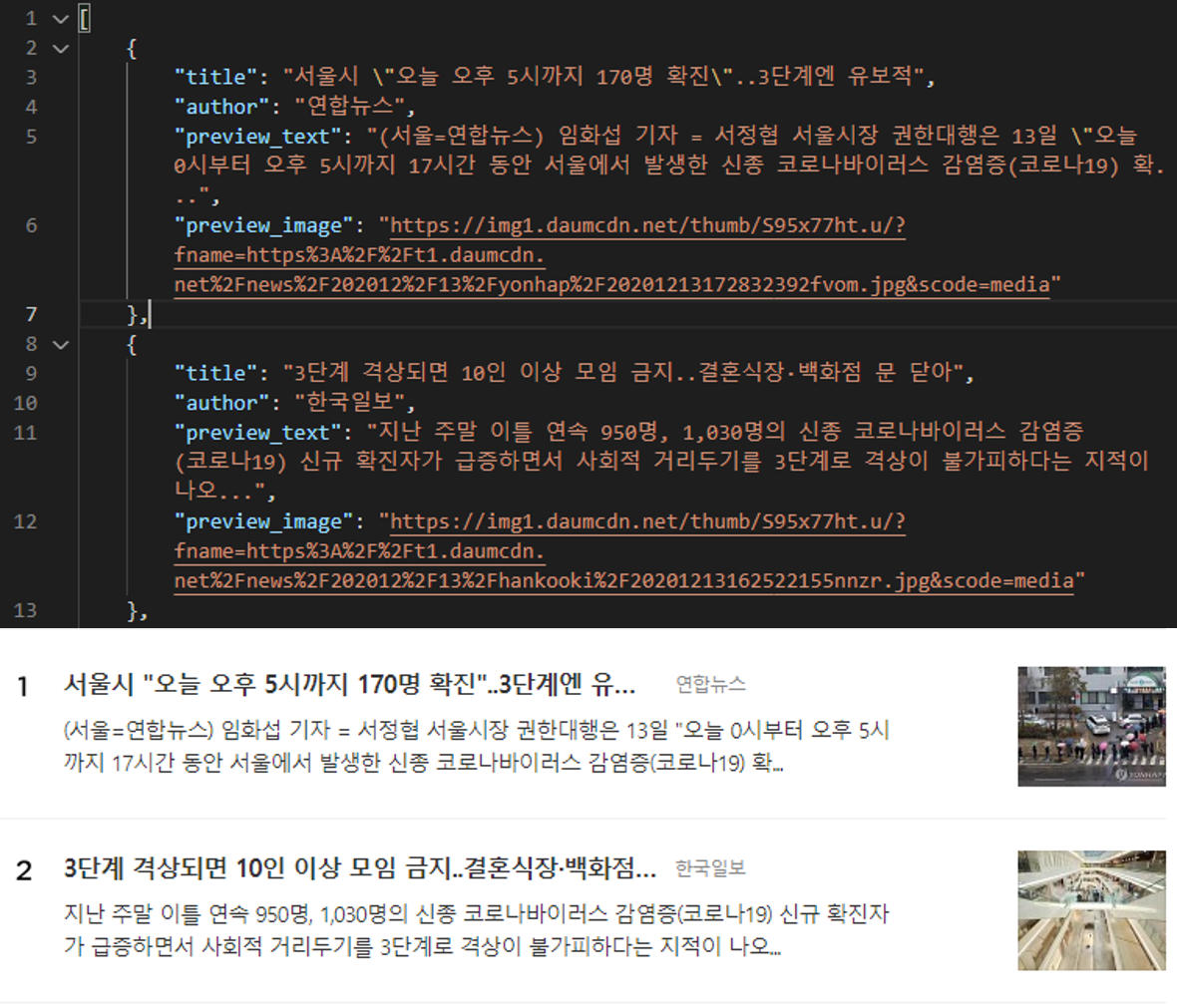
다시 작업을 실행하고 결과로 출력된 JSON 파일을 열어보면 한글로 잘 출력된 것을 확인 할 수 있다. 그리고 실제 사이트와 데이터를 비교해 보면 다음과 같이 잘 수집되었음을 확인 할 수 있을 것이다.
실제 사이트와 JSON 결과 파일 비교
데이터 수집 결과 까지 확인했으니 이제 남은 것은 주기적으로 실행되도록 하는 것인데, CRON Job을 사용하면 쉽게 Scheduling을 할 수 있다.
그런데… CRON은 무엇이 길래 Scheduling을 해준다는 것일까?
CRON이란, Unix system OS의 시간기반 Job scheduler다. 고정된 시간, 날짜, 간격에 맞춰 주기적으로 실행 할 수 있도록 scheduling을 할 수 있게 해주는데 여기에 수행할 Job(작업)을 지정해 주면 scheduling된 시점에 주기적으로 Job이 실행 되는 것이다. (좀 더 자세한 CRON에 대한 설명을 원한다면, WiKi를 참고하길 바란다.)
CRON
CRON Job이 어떤 것인지 알아보았으니 만들어 사용해 보자.
먼저, Job으로 실행될 bash script file(crawl.sh)을 아래와 같이 만들어 준다.
#!/bin/sh
# spider project가 있는 프로젝트로 이동
cd newsCrawler/spiders
# scrapy가 설치된 python의 가상환경에서 spider 실행
pipenv run scrapy crawl newsBot -o ./newsCrawler/json/result.json
그 다음 만든 Script를 아래와 같이 CRON에 추가해 주면 Crawler에 대한 Scheduling 작업이 완료된다.
# 매일 0시 0분에 Crawling 작업을 한다.
0 0 * * * /Users/Python/newsCrawler/crawl.sh
정상적으로 CRON에 등록 되었다면 매일 0시 0분에 Cralwer가 동작 할 것이고 실행 결과는 json 폴더에 업데이트 될 것이다.
참고로, CRON Job이 정상적으로 동작했다면 아래와 같은 Syslog를 확인 할 수 있다.
Dec 14 00:00:00 DESKTOP CRON[1327]: (root) CMD (/Users/Python/newsCrawler/crawl.sh)
여기까지 Scrapy 오픈소스 라이브러리를 사용하여 Web Crawling 작업을 해 보았다.
간단히 사용법을 알아보는 정도에서 구성한 것이라 좀더 자세한 설명이나 추가적인 설명이 필요하다면, Scrapy에 대한 정보는 공식문서를 참고하길 바란다.
인터넷 상에는 무수히 많은 데이터가 있다. 그리고 우리는 그것을 수집하여 활용하고 싶지만 쉽지가 않다.
예를 들어 최근 뉴스를 수집하여 트랜드를 분석한다고 한다면, 뉴스 데이터를 어디서, 어떻게 얻을 것인가?
이미 잘 정리해서 제공하는 곳이 있다면 참 좋겠지만, 현실적으로 내가 원하는 데이터가 딱맞춰 제공되는 경우는 없다고 보는게 맞다. 그렇다면 원하는 데이터를 직접 수집을 해야한다는 말인데… 어떻게 할 수 있을까?
가장 단순하게는 인터넷 포털 사이트에서 하나하나 검색해서 수집할 수도 있지만, 수집에만 들어가는 시간과 노력이 만만치 않게 들어갈 것이다.
이런 데이터 수집에 대한 어려움을 프로그래밍으로 해결할 수 있다. 그 방법은 바로 Crawling(혹은 Scraping)이란 것이다.
Crawling을 하기위한 방법들은 여러가지가 있지만, 여기서는 Python 오픈소스 라이브러리 제공되고 쉽게 사용할 수 있는 Scrapy를 사용하여 Web Crawling을 하는 방법에 대해서 알아 보겠다.
Scrapy 라이브러리를 사용하기 위해서 다음과 같이 Scrpay 패키지를 설치해야 한다.
$ pip install scrapy
설치가 완료되면 Scrapy에서 제공하는 Shell을 이용할 수 가 있다. Shell에서는 간단히 명령문으로 만으로도 쉽게 Crawling을 실행 해 볼 수 있는데, 본격적으로 Crawling 프로그래밍을 하기 전에 수집할 데이터에 대한 이해를 하기 위해서 먼저 탐색적 접근을 해 볼 수 있다는 장점이 있다.
그럼, Shell을 이용하여 데이터를 탐색하고 수집해 보겠다.
# Scrapy Shell 실행
$ scrapy shell
Shell이 실행 되었으면, 데이터 수집을 시작 할 웹 사이트 위치를 지정해 준다.
# Daum 랭킹뉴스 - 많이 본 뉴스
$ fetch('https://news.daum.net/ranking/popular')
정상적으로 실행 됬다면, Crawled라는 메시지와 함께 Response Code가 200으로 떨어지는 것을 확인 할 수 있다.
Crawler가 받은 데이터는 로컬 임시폴더(%userprofile%/AppData/Local/Temp)에 저장되어 지는데 다음과 같이 보기 명령문을 통해 데이터를 확인해 볼 수 있다.
$ view(response)
위 보기 명령문이 실행되면, HTML 페이지가 브라우저로 열릴 것이다. 그리고 해당 HTML 페이지는 실제 사이트가 아닌 로컬주소로 나타나는 것을 확인 할 수 있다. 이를 통해서 Scrapy가 웹 사이트를 Crawling하여 수집한 데이터는 HTML 페이지라는 것을 알 수 있다. 그리고 이 HTML 페이지 중에서 필요한 데이터 위치를 찾아서 추출 및 가공을 하여 유용한 데이터로 만들어 내면 되는 것이다.
그런데… HTML 페이지에서 어떻게 필요한 데이터 위치를 찾을까?
대부분의 HTML 페이지는 일종의 Document라고 할 수 있다. 그리고 Document는 DOM(Document Object Model)형태로 표현된다. 때문에 DOM을 활용하면 필요한 데이터 위치를 추적할 수 있다.
여기서 수집 하려고 하는 데이터는 다음과 같다고 정의해 보자.
제목
출처
미리보기(이미지, 글)
브라우저의 개발자 도구(F12)를 실행시켜 DOM 구조를 살펴보자.
DOM 구조와 데이터 위치
모든 뉴스는 “list_news2”라는 클래스를 속성 값으로 가진 UL Tag안에 모여 있는 것을 확인 할 수 있다. 그리고 각 수집 할 데이터 들은 그 하위 LI Tag 안에 위의 색으로 표시해둔대로 위치해 있는 것을 알 수 있다.
이제, 알아낸 데이터 위치 정보를 XPath 함수에 입력하여 필요한 데이터를 수집하면 된다.
첫 번째 수집 대상인 뉴스 기사 제목 부터 수집해 보자. XPath에 뉴스 제목의 위치 정보를 넘기기 위해서 다음과 같이 표현 할 수 있다.
이 것의 의미는 “UL Tag 중에서 list_news2라는 클래스 속성 값을 갖는 객체를 Root로 한다. Root 밑에 개별 기사는 LI Tag에 담겨 있고, 그 밑에 두 번째 DIV 밑에 STRONG 밑에 A Tag Text에 기사 제목이 있다.” 라는 것이다.
위 표현 값을 XPath 함수에 넣어 실행해 보자.
# 뉴스 기사 제목
$ response.xpath('//ul[@class="list_news2"]/li/div[2]/strong/a/text()').extract()
실행 결과로 50개의 모든 뉴스 기사 제목을 리스트 형태로 반환한 것을 확인 할 수 있다.
['[날씨] 겨울 한파 찾아온다..9일 밤부터 곳곳 눈·비',
'잘린 손가락 들고 20개 병원 전전 "코로나 아니면 치료도 못 받나요"',
'"문 대통령 취임 초기 기대 컸지만.. 지금은 아니다"',
"오보라던 '그들의 술자리'..총장도 검사들도 '조용'",
'소형 오피스텔까지 싹쓸이.."막을 방법 없다"',
.... 생략 ....
]
같은 방법으로 나머지 데이터도 수집해 보자.
# 뉴스 출처(언론사)
$ response.xpath('//ul[@class="list_news2"]/li/div[2]/strong/span/text()').extract()
# 미리 보기 글
$ response.xpath('//ul[@class="list_news2"]/li/div[2]/div[1]/span/text()').extract()
# 미리 보기 이미지 주소
$ response.xpath('//ul[@class="list_news2"]/li/a/img/@src').extract()
여기까지 잘 실행이 되었다면, Shell를 통해서 수집하려고한 대상 데이터에 대해서 Crawling이 가능하다는 것을 확인한 샘이다.
Shell 명령 코드로 수행해본 Crawling 작업이 1회성으로 데이터를 수집하고 끝나는 것이 라면 이대로 끝내면 되겠지만, 데이터를 주기적으로 추가 수집하거나 업데이트가 필요하다면, 매번 Shell 명령코드로 수행하기 어려울 것이다.
이런 부분은 Shell 명령 코드를 Crawler 모듈로 만들어서 주기적으로 실행 할 수 있으면 좋을 것이다.
다음 포스트에서는 이번 포스트에서 사용한 Shell 명령 코드를 그대로 활용하여 Spider Project를 만들고 주기적으로 데이터를 업데이트 할 수 있는 Crawler를 만들어 보겠다.
import pandas as pd
import numpy as np
import sys
from itertools import combinations, groupby
from collections import Counter
from IPython.display import display
# 데이터 파일(객체)이 어느정도 사이즈(MB) 인지 확인 하는 함수.
def size(obj):
return "{0:.2f} MB".format(sys.getsizeof(obj) / (1000 * 1000))
# 파일 저장 경로
path = "./Dataset/Instacart"
Pandas를 이용하여 주문 데이터를 읽어서 데이터의 사이즈와 차원을 확인하고 실제 데이터를 살펴 보기 위해 상위 5개 데이터를 확인해 본다.
주문 데이터는 4개의 차원으로 약 3천만 건의 주문 정보를 담고 있으며, 총 데이터의 크기는 1GB라는 것을 알 수 있다. 4개의 차원은 주문번호, 상품번호, 카트에 담긴 순서, 재(추가)주문 상태를 나타내고 있다. 여기서 연관규칙을 찾을 때 필요한 데이터는 주문번호와 상품번호만 있으면 되기 때문에 주문번호를 인덱스로 하고 상품번호를 Value로하는 Series로 변환한다.
연관규칙을 찾기 위해서는 지지도, 신뢰도, 향상도 지표를 확인하여 규칙의 효용성을 확인 해야 한다. 이 3개 지표를 계산해 내기 위한 함수를 먼저 정의한다.
# 단일 품목이나 품목 집합에 대한 빈도수를 반환한다.
def freq(iterable):
if type(iterable) == pd.core.series.Series:
return iterable.value_counts().rename("freq")
else:
return pd.Series(Counter(iterable)).rename("freq")
# 고유한 주문번호 갯수를 반환한다.
def order_count(order_item):
return len(set(order_item.index))
# 한번에 한 품목 집합을 생성하는 generator를 반환한다.
def get_item_pairs(order_item):
order_item = order_item.reset_index().values
for order_id, order_object in groupby(order_item, lambda x: x[0]):
item_list = [item[1] for item in order_object]
for item_pair in combinations(item_list, 2):
yield item_pair
# 품목에 대한 빈도수와 지지도를 반환한다.
def merge_item_stats(item_pairs, item_stats):
return (item_pairs
.merge(item_stats.rename(columns={'freq': 'freqA', 'support': 'supportA'}), left_on='item_A', right_index=True)
.merge(item_stats.rename(columns={'freq': 'freqB', 'support': 'supportB'}), left_on='item_B', right_index=True))
# 품목 이름을 반환한다.
def merge_item_name(rules, item_name):
columns = ['itemA','itemB','freqAB','supportAB','freqA','supportA','freqB','supportB',
'confidenceAtoB','confidenceBtoA','lift']
rules = (rules
.merge(item_name.rename(columns={'item_name': 'itemA'}), left_on='item_A', right_on='item_id')
.merge(item_name.rename(columns={'item_name': 'itemB'}), left_on='item_B', right_on='item_id'))
return rules[columns]
다음으로, 실제 규칙을 찾기 위해 위 지표를 구하는 함수들을 이용하여, 연관 규칙을 찾는 함수를 정의 한다.
# 미리 준비한 주문 정보(주문번호를 인덱스로 하고 상품번호를 Value로하는 Series)와 최소 지지도를 입력받아 연관 규칙을 반환한다.
def association_rules(order_item, min_support):
print("Starting order_item: {:22d}".format(len(order_item)))
# 빈도수와 지지도를 계산한다.
item_stats = freq(order_item).to_frame("freq")
item_stats['support'] = item_stats['freq'] / order_count(order_item) * 100
# 최소 지지도를 만족하지 못하는 품목은 제외한다.
qualifying_items = item_stats[item_stats['support'] >= min_support].index
order_item = order_item[order_item.isin(qualifying_items)]
print("Items with support >= {}: {:15d}".format(min_support, len(qualifying_items)))
print("Remaining order_item: {:21d}".format(len(order_item)))
# 2개 미만의 주문 정보는 제외한다.
order_size = freq(order_item.index)
qualifying_orders = order_size[order_size >= 2].index
order_item = order_item[order_item.index.isin(qualifying_orders)]
print("Remaining orders with 2+ items: {:11d}".format(len(qualifying_orders)))
print("Remaining order_item: {:21d}".format(len(order_item)))
# 빈도수와 지지도를 다시 계산한다.
item_stats = freq(order_item).to_frame("freq")
item_stats['support'] = item_stats['freq'] / order_count(order_item) * 100
# 품목 집합에 대한 generator를 생성한다.
item_pair_gen = get_item_pairs(order_item)
# 품목 집합의 빈도수와 지지도를 계산한다.
item_pairs = freq(item_pair_gen).to_frame("freqAB")
item_pairs['supportAB'] = item_pairs['freqAB'] / len(qualifying_orders) * 100
print("Item pairs: {:31d}".format(len(item_pairs)))
# 최소 지지도를 만족하지 못하는 품목 집합을 제외한다.
item_pairs = item_pairs[item_pairs['supportAB'] >= min_support]
print("Item pairs with support >= {}: {:10d}\n".format(min_support, len(item_pairs)))
# 계산된 연관 규칙을 계산된 지표들과 함께 테이블로 만든다.
item_pairs = item_pairs.reset_index().rename(columns={'level_0': 'item_A', 'level_1': 'item_B'})
item_pairs = merge_item_stats(item_pairs, item_stats)
item_pairs['confidenceAtoB'] = item_pairs['supportAB'] / item_pairs['supportA']
item_pairs['confidenceBtoA'] = item_pairs['supportAB'] / item_pairs['supportB']
item_pairs['lift'] = item_pairs['supportAB'] / (item_pairs['supportA'] * item_pairs['supportB'])
# 향상도를 내림차순으로 정렬하여 연관 규칙 결과를 반환한다.
return item_pairs.sort_values('lift', ascending=False)
연관 규칙을 찾기 위한 데이터와 프로그램(함수) 준비가 완료 되었다.
연관규칙을 찾아보자.
%%time
rules = association_rules(orders, 0.01)
Starting order_item: 32434489
Items with support >= 0.01: 10906
Remaining order_item: 29843570
Remaining orders with 2+ items: 3013325
Remaining order_item: 29662716
Item pairs: 30622410
Item pairs with support >= 0.01: 48751
Wall time: 6min 24s
출력된 결과를 확인해보자. 약 3천만 건의 주문 정보에서 최소 지지도 0.01를 넘는 약 4만 8천건의 연관 규칙을 찾아 내었고, 연관 규칙을 만들어 내는 데 걸린 시간은 6분 24초가 걸렸다는 것을 알 수 있다.
찾은 결과를 출력해 보자.
# 품목 ID를 보기 좋게 하기 위해서 품목 이름으로 바꿔준다.
item_name = pd.read_csv(path + '/products.csv')
item_name = item_name.rename(columns={'product_id':'item_id', 'product_name':'item_name'})
rules_final = merge_item_name(rules, item_name).sort_values('lift', ascending=False)
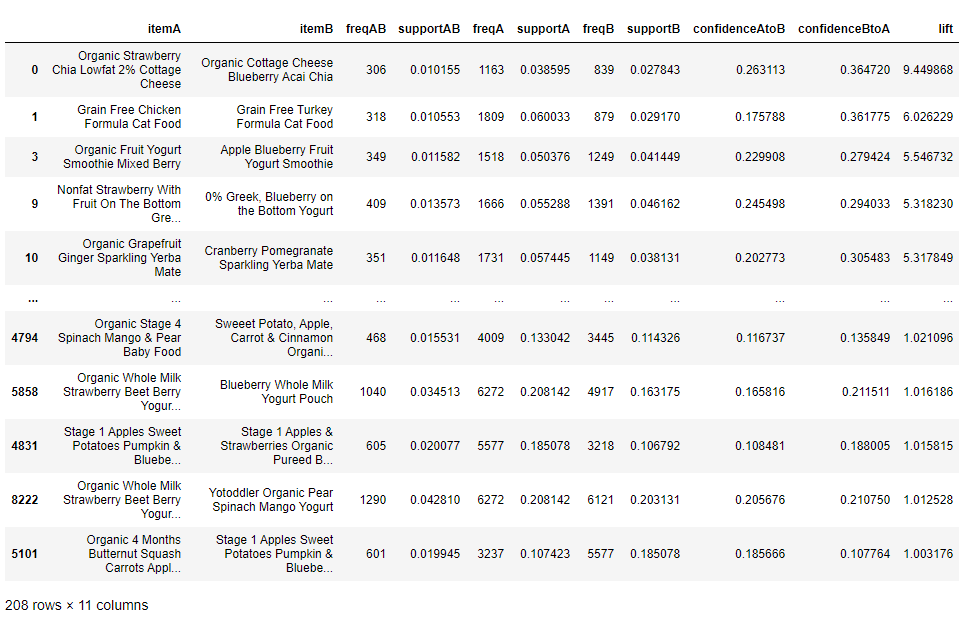
display(rules_final)
연관 규칙 결과 테이블
출력된 연관 규칙 테이블을 보면 다소 복잡해 보일 수 있으나, 맨 마지막 열의 향상도(lift)를 보면 품목 간의 관계를 확인 할 수 있다.
lift = 1, 품목간의 관계 없다. *예: 우연히, 같이 사게되는 경우
lift > 1, 품목간의 긍정적인 관계가 있다. *예: 같이 사는 경우
lift < 1, 품목간의 부정적인 관계가 있다. *예: 같이 사지 않는 경우
출력된 향상도를 이용하여 결과를 분석해보자.
먼저, 품목 간의 긍정적인 관계인 향상도가 1 보다 큰 결과를 살펴 보자.
코티지 치즈는 블루베리 아사이 맛과 딸기 치아 맛을 같이 구매한다.
고양이 먹이는 치킨 맛과 칠면조 맛을 같이 구매한다.
요거트는 믹스 베리 맛과 사과 블루베리 맛을 같이 구매한다.
위 결과를 토대로 생각해 보면, 대부분 구입한 한 가지 품목에 대해서 다른 맛을 내는 같은 품목을 같이 구입한다는 것을 알 수 있다.
다음으로, 품목 간의 부정적인 관계인 향상도가 1보다 작은 결과를 보자.
유기농 바나나를 사는 경우 일반 바나나는 사지 않는다.
일반 품종의 아보카도를 구입한 경우 하스 아보카도를 구입하지 않는다.
유기농 딸기를 사는 경우 일반 딸기를 사지 않는다.
이번 결과에서는 구입한 한 가지 품목에 대해서 다른 생산과정 혹은 영양구성의 같은 품목은 같이 구입하지 않는다는 것을 알 수 있다.
이전 포스팅에서 언급했듯이, 단순히 나열된 구매 정보만으로는 확인 할 수 없었던 규칙들을 연관 분석을 통해서 알아 낼 수 있게 되었다. 이러한 정보를 바탕으로 고객들에게 제품을 추천 한다거나 상품의 배열을 바꿔 줄 수 있다면 상품 판매에 의미 있는 결과를 얻을 수 있을 거라 생각한다.
text 데이터를 처리하다 보면 그 안에 개인정보(phone, email 등) 등의 민감정보가 포함 되어 있는 경우가 있다. 이것들은 정규식(regular expression)을 사용하여 알아 볼 수 없도록 편집 (masking) 할 수 있다.
import re
text = '안녕하세요. 문의드릴 것이 있어서 연락드렸습니다. 제 연락처는 010-1234-1234 / thenewth@gmail.com 입니다. 연락가능 하실때 연락 부탁 드립니다. 감사합니다.'
phoneRegular = "\d{2,3}-\d{3,4}-\d{4}"
emailReqular = "(\w+\.)*\w+@(\w+\.)+[A-Za-z]+"
phonePattern = re.compile(phoneRegular)
emailPattern = re.compile(emailReqular)
#Masking 문자 대신 공백을 사용하면 민감정보 표시 자체를 삭제 할 수 있다.
redactedPhoneText = re.sub(phonePattern, "***-****-****", text)
redactedEmailText = re.sub(emailPattern , "****@****.***", text)
#전화번호 정보 masking 결과 확인
print(redactedPhoneText)
#이메일 정보 masking 결과 확인
print(redactedEmailText)
출력한 결과를 확인해 보면 정규식에 해당하는 민감정보가 편집(Masking)된 것을 확인 할 수 있다.
import json
import pymssql
#[Tip]json 문자열을 환경변수 파일로 저장하여 사용한다면 서버정보를 노출 하지 않을 수 있다.
json_string =
'{
"host":"Server Address",
"port":1433,
"user":"User ID@Server Name",
"password":"P@ssW0rd",
"database":"Database Name"
}'
json_data = json.load(json_string)
#pymssql 모듈을 이용하여 Connection 생성을 한다.
conn = pymssql.connect(host=json_data['host'], port=json_data['port'], user=json_data['user'], password=json_data['password'], database=json_data['database'])
여기까지 하면 MS-SQL서버에 접근(Connection 완료) 한 것이다. 다음으로 Select query문을 실행하여 데이터를 가져와 보자.
#Connection으로부터 cursor 생성
cursor = conn.cursor()
#Select Query 실행
cursor.execute('select * from [Target Table Name]')
#결과 데이터를 데이터프레임에 저장
df = pd.DataFrame(cursor.fetchall())
#실행이 끝나면 항상 연결 객체를 닫아 주어야 한다.
conn.close()