지난 포스트에서는 Scrapy Shell에서 간단한 명령 코드를 이용하여 간단히 Web Crawling을 수행해 보았다.
이번에는 지난 포스트에서 작성한 Shell 명령 코드를 활용하여 Spider Project를 만들어서 데이터를 주기적으로 업데이트 할 수 있는 Crawler 모듈을 만들어 보겠다.
그럼, Spider Project를 만들어 보자.
아래와 같이 Project를 구성할 위치에서 명령어를 실행해보자.
# newsCrawler라는 Spider Project를 만든다.
$ scrapy startproject newsCrawler
명령 실행이 완료 되면, 다음과 같은 메시지가 나오면서 Start Project가 만들어 진것을 확인 할 수 있다.
You can start your first spider with:
cd newsCrawler
scrapy genspider example example.com이제, newsCrawler라고 만든 프로젝트를 이용하여 Crawler 모듈 개발 작업을 시작하면 되는데… 그전에 먼저, Project의 구성에 대해서 간단히 알아보도록 하자.
- newsCrawler/ # Root Directory
- scrapy.cfg # 프로젝트 설정 파일
- newsCrawler/ # 프로젝트 공간
- __init__.py
- items.py # Spider가 작업을 완료한 후 반환하는 결과 값의 Schema를 정의하는 파일
- middlewares.py # Spider가 요청을 보낼 때 process를 제어하는 파일
- pipelines.py # Spider가 응답을 받았을 때 process를 제어하는 파일
- settings.py # Spider 실행에 필요한 전반적인 옵션을 설정하는 파일
- spiders/ # 데이터를 수집 가공하는 Spider(Crawler) 모듈을 개발하는 공간, 여러개의 Spider가 있을 수 있다.
- __init__py
위 프로젝트 구성을 보면 “nwesCrawler/spider”라는 위치에서 Spider(Crawler)를 개발하면 되는 것을 알 수 있다.
해당 위치로 이동하여 아래와 같이 Spider(Crawler) 생성 명령을 실행해 보자.
# Project의 spiders폴더로 이동하여 newsBot이라는 Spider를 생성한다.
$ cd newsCrawler/spiders
$ scrapy genspider newsBot 'news.daum.net/ranking/popular'
명령 실행이 완료되면 다음과 같이 기본 Template이 생성되었다는 메시지를 확인 할 수 있다.
Created spider 'newsBot' using template 'basic' in module:
{spiders_module.__name__}.{module}이제, 만들어진 Template(newsBot.py)에 이전에 만들어둔 Shell 명령 코드를 넣어서 Spiders(Crawler) 모듈 개발 작업을 하면 된다.
import scrapy
class NewsbotSpider(scrapy.Spider):
name = 'newsBot'
allowed_domains = ['news.daum.net/ranking/popular']
start_urls = ['http://news.daum.net/ranking/popular/']
def parse(self, response):
# Web Crawling with Scrapy(1) 참고
titles = response.xpath('//ul[@class="list_news2"]/li/div[2]/strong/a/text()').extract()
authors = response.xpath('//ul[@class="list_news2"]/li/div[2]/strong/span/text()').extract()
previews_text = response.xpath('//ul[@class="list_news2"]/li/div[2]/div[1]/span/text()').extract()
previews_image = response.xpath('//ul[@class="list_news2"]/li/a/img/@src').extract()
for item in zip(titles, authors, previews_text, previews_image):
scraped_info = {
'title': item[0].strip(),
'author': item[1].strip(),
'preview_text': item[2].strip(),
'preview_image': item[3].strip()
}
yield scraped_info
개발 작업 완료되었으면, 아래와 같이 newsBot을 실행시켜 보자.
# newsBot 실행하고 결과는 JSON 파일로 지정위치에 출력한다.
$ scrapy crawl newsBot -o ./newsCrawler/json/result.json
실행이 완료되면 결과가 지정된 위치 “newsCrawler/json”에 JSON 파일로 만들어 진 것을 확인 할 수 있다.
그런데 JSON 파일을 열어보면 다음과 같이 Unicode로 결과가 출력되어 데이터가 잘 수집된 것인지 확인 하기가 어렵다.
[
{
"title": "\ubb38 \ub300\ud1b5\ub839 \"3\ub2e8\uacc4 \uaca9\uc0c1\uc740 \ub9c8\uc9c0\ub9c9 \uc218\ub2e8..\ubd88\uac00\ud53c\ud558\uba74 \uacfc\uac10\ud788 \uacb0\ub2e8\"",
"author": "\uacbd\ud5a5\uc2e0\ubb38",
"preview_text": "[\uacbd\ud5a5\uc2e0\ubb38] \ubb38\uc7ac\uc778 \ub300\ud1b5\ub839\uc740 13\uc77c \ucf54\ub85c\ub09819 \ud655\uc9c4\uc790\uac00 \uae09\ub4f1\uc138\ub97c \ubcf4\uc774\ub294 \uac83\uacfc \uad00\ub828, \u201c\uc9c0\uae08 \ud655\uc0b0\uc138\ub97c \uaebe\uc9c0 \ubabb\ud558\uba74 \uc0ac\ud68c\uc801 \uac70\ub9ac\ub450\uae30 3\ub2e8\uacc4 \uaca9\uc0c1\ub3c4 \uac80\ud1a0\ud574\uc57c \ud558\ub294 \uc911\ub300\ud55c \uad6d...",
"preview_image": "https://img1.daumcdn.net/thumb/S95x77ht.u/?fname=https%3A%2F%2Ft1.daumcdn.net%2Fnews%2F202012%2F13%2Fkhan%2F20201213154335225ujgt.jpg&scode=media"
},
..... 생략 .....
]
출력 결과를 알아보기 쉽게 한글로 표현하기 위해서는 settings.py에 출력결과가 utf-8로 인코딩될 수 있도록 설정을 추가 해주면 된다.
FEED_EXPORT_ENCODING = 'utf-8'
설정 내용을 저장하고 다시한번 newsBot을 실행 시켜보자.
다시 작업을 실행하고 결과로 출력된 JSON 파일을 열어보면 한글로 잘 출력된 것을 확인 할 수 있다. 그리고 실제 사이트와 데이터를 비교해 보면 다음과 같이 잘 수집되었음을 확인 할 수 있을 것이다.
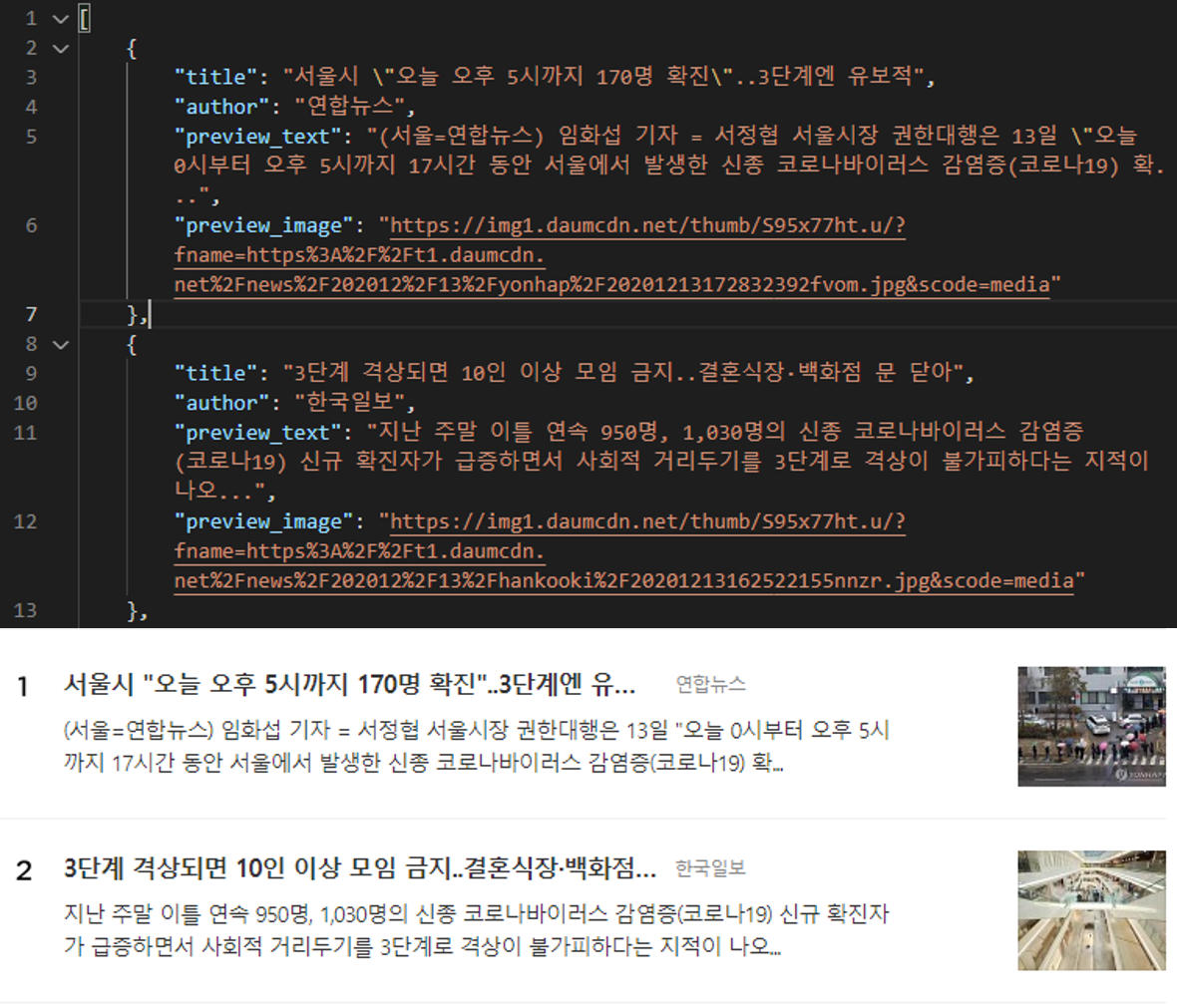
데이터 수집 결과 까지 확인했으니 이제 남은 것은 주기적으로 실행되도록 하는 것인데, CRON Job을 사용하면 쉽게 Scheduling을 할 수 있다.
그런데… CRON은 무엇이 길래 Scheduling을 해준다는 것일까?
CRON이란, Unix system OS의 시간기반 Job scheduler다. 고정된 시간, 날짜, 간격에 맞춰 주기적으로 실행 할 수 있도록 scheduling을 할 수 있게 해주는데 여기에 수행할 Job(작업)을 지정해 주면 scheduling된 시점에 주기적으로 Job이 실행 되는 것이다.
(좀 더 자세한 CRON에 대한 설명을 원한다면, WiKi를 참고하길 바란다.)

CRON Job이 어떤 것인지 알아보았으니 만들어 사용해 보자.
먼저, Job으로 실행될 bash script file(crawl.sh)을 아래와 같이 만들어 준다.
#!/bin/sh
# spider project가 있는 프로젝트로 이동
cd newsCrawler/spiders
# scrapy가 설치된 python의 가상환경에서 spider 실행
pipenv run scrapy crawl newsBot -o ./newsCrawler/json/result.json
그 다음 만든 Script를 아래와 같이 CRON에 추가해 주면 Crawler에 대한 Scheduling 작업이 완료된다.
# 매일 0시 0분에 Crawling 작업을 한다.
0 0 * * * /Users/Python/newsCrawler/crawl.sh
정상적으로 CRON에 등록 되었다면 매일 0시 0분에 Cralwer가 동작 할 것이고 실행 결과는 json 폴더에 업데이트 될 것이다.
참고로, CRON Job이 정상적으로 동작했다면 아래와 같은 Syslog를 확인 할 수 있다.
Dec 14 00:00:00 DESKTOP CRON[1327]: (root) CMD (/Users/Python/newsCrawler/crawl.sh)여기까지 Scrapy 오픈소스 라이브러리를 사용하여 Web Crawling 작업을 해 보았다.
간단히 사용법을 알아보는 정도에서 구성한 것이라 좀더 자세한 설명이나 추가적인 설명이 필요하다면, Scrapy에 대한 정보는 공식문서를 참고하길 바란다.

“Web Crawling with Scrapy(2)” 글에 관한 1개의 생각