Similar image search by image or natural language(1)에서는 이미지 간의 유사도를 측정해서 유사한 이미지를 찾도록 하였다. 이번 포스트에서는 자연어를 이용해서 자연어에서 설명하는 이미지와 유사한 이미지를 찾는 방법에 대해서 알아보겠다.
CLIP model은 Text로 들어오는 자연어를 Transformer 아키텍처를 사용해서 처리한다. 입력된 Text는 Tokenize되어 Embeding 된 후에 여러 개 층으로 구성된 Transformer 인코더를 통해 처리됩니다. 처리된 자연어는 Vector값으로 반환 되고, 자연어의 의미와 문맥이 어떤 이미지를 의미 하는 지를 512 차원의 Vector 값으로 나타내게 됩니다.
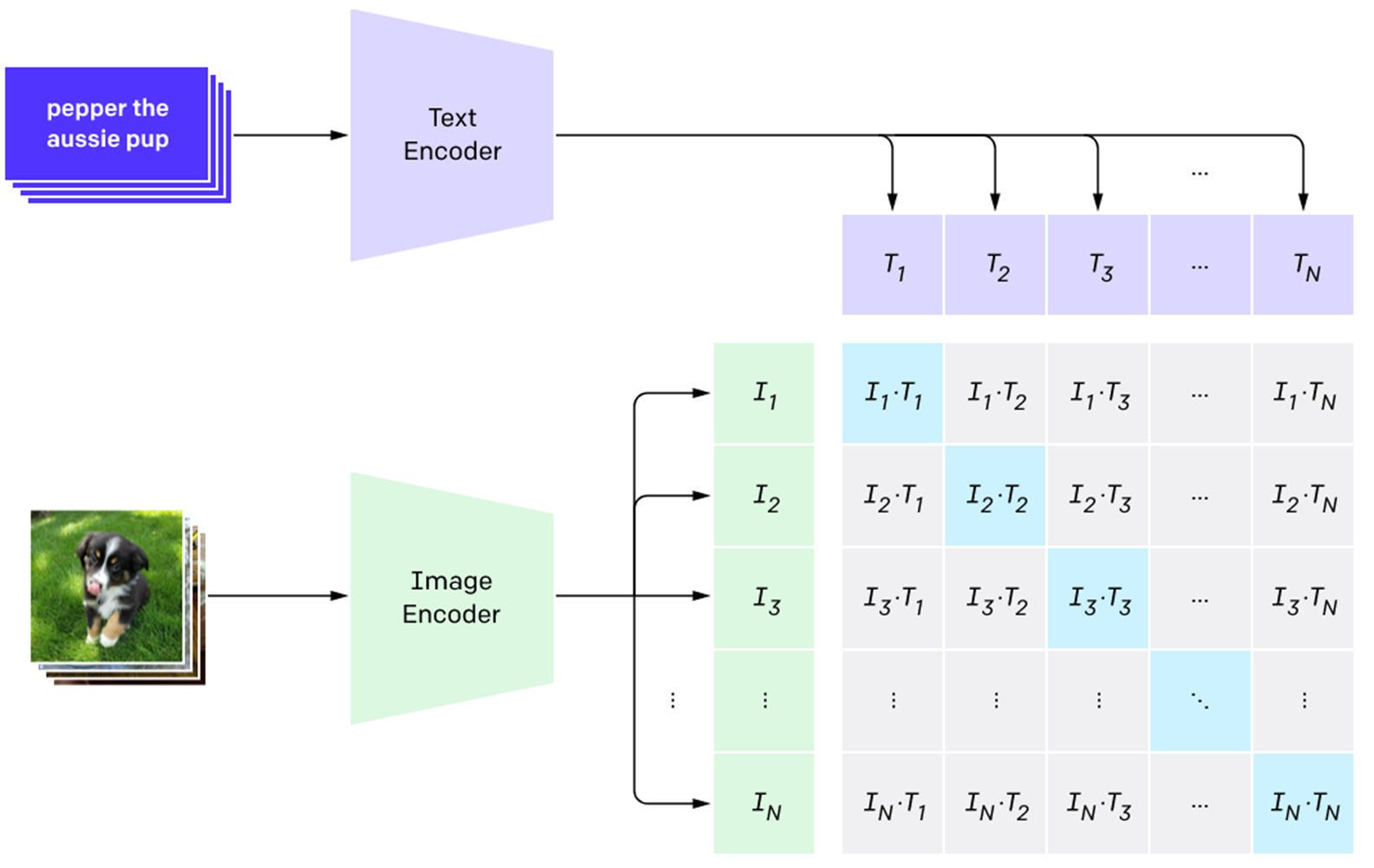
이제, CLIP을 사용해서 검색에 사용할 자연어를 vector embedding해보자.
(이전 포스트에서 이미지를 vector embedding 하던 코드를 조금 변형해서 사용하면 된다.)
from sentence_transformers import SentenceTransformer
from PIL import Image
# 영어 모델 clip-ViT-B-32
# 다국어 모델 clip-ViT-B-32-multilingual-v1
img_model = SentenceTransformer('clip-ViT-B-32-multilingual-v1', device='cpu')
def vectorize(text):
embedding = img_model.encode(text)
return embedding.tolist()
vectorize('빨간 사과')
위 코드를 실행해보면 텍스트가 vector embedding되어 512 차원의 vector를 반환하는 것을 확인 할 수 있다. 반환 받은 vector 값을 이용하여서 이미지 검색을 해보자.
GET image_vector/_search
{
"knn": {
"field": "vector",
"k": 5,
"num_candidates": 10,
"query_vector": [
-0.10659506916999817,
0.20013009011745453,
0.15304496884346008,
0.03850187361240387,
-0.126994326710701,
... 생략 ...
-0.04996727779507637
]
},
"fields": [
"image_name"
],
"_source": false
}

결과를 보면 빨간 사과라는 자연어 Text에서 “빨간”과 “사과”의 의미를 잘 파악해서 이미지를 잘 찾아 낸 것을 볼 수 있다.



