대규모 언어 모델(LLM, Large Language Model)의 학습은 수십억 개 이상의 파라미터를 다루기 때문에, 단일 GPU의 메모리나 연산 능력으로는 처리하기 어렵다. 이러한 문제를 해결하기 위해 병렬화(parallelism) 전략이 도입되며, 주로 두 가지 방식인 모델 병렬화(Model Parallelism) 와 데이터 병렬화(Data Parallelism)가 사용된다.
Model Parallelism
모델 병렬화는 하나의 모델을 여러 GPU에 분산시켜 학습하는 방식입니다. 모델이 너무 커서 단일 GPU 메모리에 올릴 수 없을 때 사용된다. 대표적인 두 가지 방식이 있다.
Pipeline Parallelism
딥러닝 모델의 층(Layer) 단위로 모델을 분할하고, 각 분할을 다른 GPU에 할당한다.
입력 데이터가 GPU를 순차적으로 통과하며 forward/backward 연산이 수행된다.
모델 크기를 효과 적으로 분산 할 수 있지만, 각 GPU가 순차적으로 동작하게 되어서 파이프라인 버블 문제가 생길 수 있다.
그림에서 머신을 1, 2와 3, 4로 나누면 파이프라인 병렬화이다.
Tensor Parallelism
하나의 층 내부에서 계산되는 텐서 연산을 여러 GPU에 나누어 수행한다.
행렬 곱 연산에서 행 또는 열을 나눠 병렬 연산 후 결과를 합치는 연산을 하면서 수행된다.
레이어 수준보다 더 미세하게 병렬화할 수 있어서 계산량을 세밀하게 분산이 가능하지만, GPU간 통신이 빈번하게 발생하게 되어 통신 오버헤드가 커질 수 있음.
그림에서 머신을 1, 3과 2, 4로 나누면 텐서 병렬화이다.
Model Parallelism
Data Parallelism
모델 크기가 하나의 GPU에 올라가기 적당하고 데이터가 많을 경우 사용할 수 있는 방식으로 데 모델을 그대로 복제한 후, 서로 다른 GPU에서 다른 데이터를 학습시키는 방식이다.
그림 처럼 각 GPU는 동일한 모델을 가지고 있으며, 각기 다른 미니배치 데이터를 학습한다.
Data Parallelism
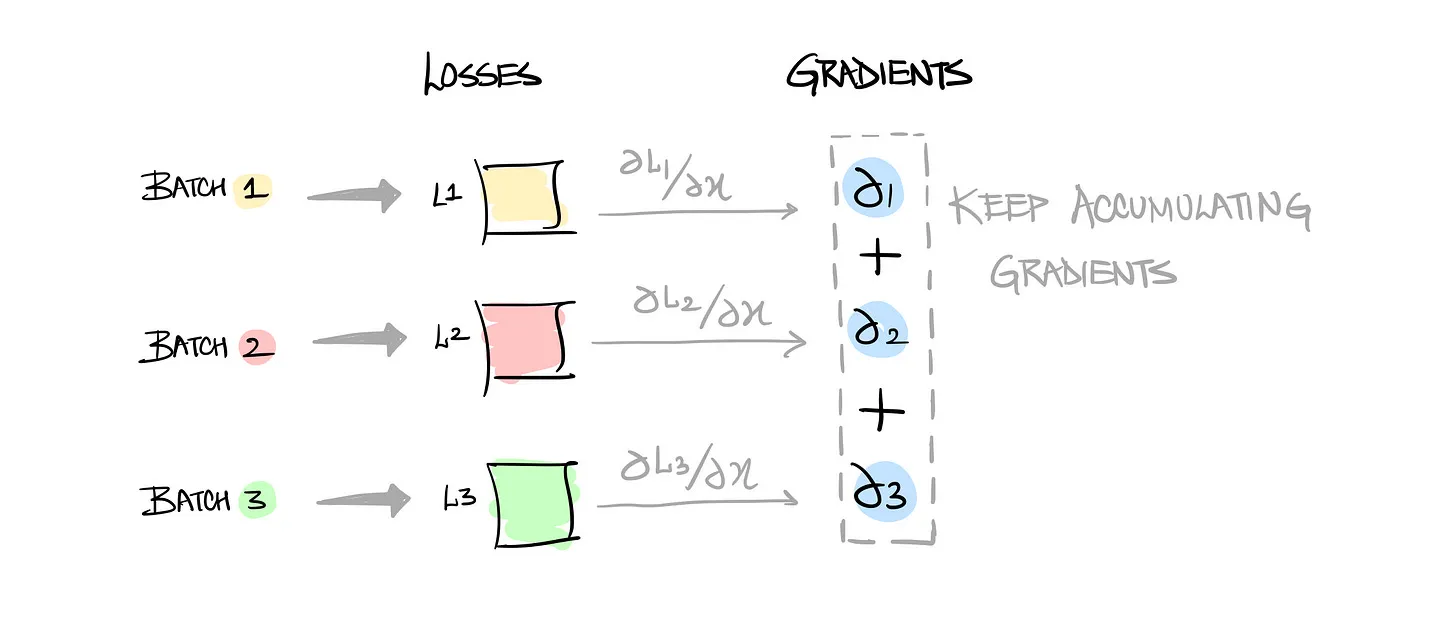
forward/backward 연산 후, 파라미터의 그레이디언트(gradient) 를 모든 GPU가 서로 동기화하여 업데이트한다.
구현이 간단하고 대부분의 프레임워크에서 지원이 되지만, 모델 크기가 GPU 메모리에 들어가야 하고, 모든 GPU 간의 gradient 통신 비용이 크다.
LLM 모델 학습은 단순히 모델을 만드는 것 이상으로 효율적인 리소스 분산이 핵심이다. 모델 크기, 하드웨어 환경, 통신 병목 등을 고려하여 파이프라인 병렬화, 텐서 병렬화, 데이터 병렬화를 적절히 조합여 사용해야 한다.
대규모 언어 모델(LLM)을 학습하거나 미세 조정할 때 가장 큰 제약 중 하나는 GPU 메모리 부족이다. 학습 과정에서 어떤 데이터가 메모리에 올라가는지, 이를 어떻게 줄일 수 있는지 정리해 보자.
GPU 메모리에 저장되는 주요 데이터
Model Parameters
모델 가중치(Weight)와 편향(Bias) 등의 학습 가능한 값.
예를 들어 7B (7 Billion) 파라미터 모델의 경우 FP32 기준 약 28GB 메모리가 필요함.
Gradient
각 파라미터에 대해 손실 함수의 기울기 값
역전파(Back propagation) 과정에서 계산되며, 파라미터와 같은 크기의 메모리를 필요로 함.
Optimizer State
Optimizer는 모델을 학습시키기 위해 파라미터를 업데이트 하는 알고리즘임. 이때 대부분의 고급 옵티마이저는 각 파라미터마다 추가적인 정보를 저장하는데 이 정보들이 Optimizer State임.
예를 들어 Adam 옵티마이저는 각 파라미터에 대해 1st moment (이전 기울기의 평균), 2nd moment (기울기 제곱의 평균) 추적 값을 저장함.
파라미터 크기의 2~3배에 달하는 추가 메모리 소모가 발생할 수 있음.
Forward Activation
순전파(Forward pass)에서 중간 레이어의 출력값.
역전파 시 Gradient를 계산하기 위해 반드시 필요한 값.
가장 많은 메모리를 차지할 수 있음.
메모리 절약을 위한 전략
Gradient Accumulation
GPU 메모리 한계를 넘지 않기 위해 작은 배치(batch) 크기로 여러 번 계산하고 그래디언트를 누적(accumulate).
일정 스텝마다 누적된 그래디언트를 이용해 파라미터를 한 번 업데이트함.
Batch size 16에서 OOM이 발생할 경우 -> Batch size 4 (gradient_accumulation_steps=4)로 설정. -> Loss를 4로 나누어 누적하면 batch size 16과 동일한 학습 효과를 얻을 수 있음. -> 실제 메모리 사용량은 Batch size 4로 계산 됨. -> 작은 Batch size로 큰 Batch size로 학습로 학습한 것과 동일한 효과를 얻을 수 있지만 누적 연산을 추가로 해야 해서 학습 시간은 증가됨.
Checkpointing (Activation Checkpointing)
순전파 시 전체 activation을 저장하지 않고, 마지막 출력값만 저장.
역전파 시 필요한 이전 상태는 다시 계산하여 사용.
순전파 상태 값을 모두 저장하지 않아서 메모리 사용량은 대폭 감소되지만, 역전파 시 순전파를 매번 반복 계산하므로 연산량 증가하여 학습 시간은 증가됨.
Gradient Checkpointing
순전파의 일부 중간 지점(checkpoint)만 저장하고 나머지는 역전파 시 재계산.
전체를 저장하는 일반 방식과, 끝만 저장하는 기본 checkpointing의 중간 전략.
메모리 효율과 연산 효율을 적절히 절충한 방식이라 약간의 오버헤드는 존재하지만 일반적인 Checkpointing 보다는 효율적임.
GPU 메모리는 LLM 학습에서 가장 중요한 자원 중 하나이다. 위에서 소개한 전략들을 적절히 활용하면 제한된 자원 내에서도 효율적으로 모델을 학습시킬 수 있다.
AI 모델 학습과 추론에서 부동소수점(Floating Point) 형식은 성능과 정확도에 큰 영향을 준다. 특히, 연산 속도와 메모리 사용량을 줄이기 위해 다양한 정밀도의 부동소수점 형식이 사용되는데, 대표적으로 사용되는 BF16, FP32, FP16에 대해 간단히 정리해 본다.
FP32 (Single Precision Floating Point)
Exponent – 8 Bit
Mantissa – 23 Bit
Sign – 1 Bit
Total 32 Bit
높은 정밀도와 넓은 표현 범위를 모두 갖춘 표준 부동소수점 형식. 대부분의 AI 학습, 고정밀 연산이 필요한 경우 사용한다.
FP16 (Half Precision Floating Point)
Exponent – 5 Bit
Mantissa – 10 Bit
Sign – 1 Bit
Total 16 Bit
정밀도와 표현 범위 모두 FP32보다 줄어들지만, 메모리 절약과 연산 속도는 증가 시킬 수 있다.
BF16 (bfloat16, Brain Floating Point Format)
Exponent – 8 Bit
Mantissa – 7 Bit
Sign – 1 Bit
Total 16 Bit
FP16과 마찬가지로 16 Bit를 사용하여 표현 범위가 줄어들었지만, FP32와 동일한 지수부를 가져서 표현 가능한 수의 범위가 넓다.
import pandas as pd
import numpy as np
import sys
from itertools import combinations, groupby
from collections import Counter
from IPython.display import display
# 데이터 파일(객체)이 어느정도 사이즈(MB) 인지 확인 하는 함수.
def size(obj):
return "{0:.2f} MB".format(sys.getsizeof(obj) / (1000 * 1000))
# 파일 저장 경로
path = "./Dataset/Instacart"
Pandas를 이용하여 주문 데이터를 읽어서 데이터의 사이즈와 차원을 확인하고 실제 데이터를 살펴 보기 위해 상위 5개 데이터를 확인해 본다.
주문 데이터는 4개의 차원으로 약 3천만 건의 주문 정보를 담고 있으며, 총 데이터의 크기는 1GB라는 것을 알 수 있다. 4개의 차원은 주문번호, 상품번호, 카트에 담긴 순서, 재(추가)주문 상태를 나타내고 있다. 여기서 연관규칙을 찾을 때 필요한 데이터는 주문번호와 상품번호만 있으면 되기 때문에 주문번호를 인덱스로 하고 상품번호를 Value로하는 Series로 변환한다.
연관규칙을 찾기 위해서는 지지도, 신뢰도, 향상도 지표를 확인하여 규칙의 효용성을 확인 해야 한다. 이 3개 지표를 계산해 내기 위한 함수를 먼저 정의한다.
# 단일 품목이나 품목 집합에 대한 빈도수를 반환한다.
def freq(iterable):
if type(iterable) == pd.core.series.Series:
return iterable.value_counts().rename("freq")
else:
return pd.Series(Counter(iterable)).rename("freq")
# 고유한 주문번호 갯수를 반환한다.
def order_count(order_item):
return len(set(order_item.index))
# 한번에 한 품목 집합을 생성하는 generator를 반환한다.
def get_item_pairs(order_item):
order_item = order_item.reset_index().values
for order_id, order_object in groupby(order_item, lambda x: x[0]):
item_list = [item[1] for item in order_object]
for item_pair in combinations(item_list, 2):
yield item_pair
# 품목에 대한 빈도수와 지지도를 반환한다.
def merge_item_stats(item_pairs, item_stats):
return (item_pairs
.merge(item_stats.rename(columns={'freq': 'freqA', 'support': 'supportA'}), left_on='item_A', right_index=True)
.merge(item_stats.rename(columns={'freq': 'freqB', 'support': 'supportB'}), left_on='item_B', right_index=True))
# 품목 이름을 반환한다.
def merge_item_name(rules, item_name):
columns = ['itemA','itemB','freqAB','supportAB','freqA','supportA','freqB','supportB',
'confidenceAtoB','confidenceBtoA','lift']
rules = (rules
.merge(item_name.rename(columns={'item_name': 'itemA'}), left_on='item_A', right_on='item_id')
.merge(item_name.rename(columns={'item_name': 'itemB'}), left_on='item_B', right_on='item_id'))
return rules[columns]
다음으로, 실제 규칙을 찾기 위해 위 지표를 구하는 함수들을 이용하여, 연관 규칙을 찾는 함수를 정의 한다.
# 미리 준비한 주문 정보(주문번호를 인덱스로 하고 상품번호를 Value로하는 Series)와 최소 지지도를 입력받아 연관 규칙을 반환한다.
def association_rules(order_item, min_support):
print("Starting order_item: {:22d}".format(len(order_item)))
# 빈도수와 지지도를 계산한다.
item_stats = freq(order_item).to_frame("freq")
item_stats['support'] = item_stats['freq'] / order_count(order_item) * 100
# 최소 지지도를 만족하지 못하는 품목은 제외한다.
qualifying_items = item_stats[item_stats['support'] >= min_support].index
order_item = order_item[order_item.isin(qualifying_items)]
print("Items with support >= {}: {:15d}".format(min_support, len(qualifying_items)))
print("Remaining order_item: {:21d}".format(len(order_item)))
# 2개 미만의 주문 정보는 제외한다.
order_size = freq(order_item.index)
qualifying_orders = order_size[order_size >= 2].index
order_item = order_item[order_item.index.isin(qualifying_orders)]
print("Remaining orders with 2+ items: {:11d}".format(len(qualifying_orders)))
print("Remaining order_item: {:21d}".format(len(order_item)))
# 빈도수와 지지도를 다시 계산한다.
item_stats = freq(order_item).to_frame("freq")
item_stats['support'] = item_stats['freq'] / order_count(order_item) * 100
# 품목 집합에 대한 generator를 생성한다.
item_pair_gen = get_item_pairs(order_item)
# 품목 집합의 빈도수와 지지도를 계산한다.
item_pairs = freq(item_pair_gen).to_frame("freqAB")
item_pairs['supportAB'] = item_pairs['freqAB'] / len(qualifying_orders) * 100
print("Item pairs: {:31d}".format(len(item_pairs)))
# 최소 지지도를 만족하지 못하는 품목 집합을 제외한다.
item_pairs = item_pairs[item_pairs['supportAB'] >= min_support]
print("Item pairs with support >= {}: {:10d}\n".format(min_support, len(item_pairs)))
# 계산된 연관 규칙을 계산된 지표들과 함께 테이블로 만든다.
item_pairs = item_pairs.reset_index().rename(columns={'level_0': 'item_A', 'level_1': 'item_B'})
item_pairs = merge_item_stats(item_pairs, item_stats)
item_pairs['confidenceAtoB'] = item_pairs['supportAB'] / item_pairs['supportA']
item_pairs['confidenceBtoA'] = item_pairs['supportAB'] / item_pairs['supportB']
item_pairs['lift'] = item_pairs['supportAB'] / (item_pairs['supportA'] * item_pairs['supportB'])
# 향상도를 내림차순으로 정렬하여 연관 규칙 결과를 반환한다.
return item_pairs.sort_values('lift', ascending=False)
연관 규칙을 찾기 위한 데이터와 프로그램(함수) 준비가 완료 되었다.
연관규칙을 찾아보자.
%%time
rules = association_rules(orders, 0.01)
Starting order_item: 32434489
Items with support >= 0.01: 10906
Remaining order_item: 29843570
Remaining orders with 2+ items: 3013325
Remaining order_item: 29662716
Item pairs: 30622410
Item pairs with support >= 0.01: 48751
Wall time: 6min 24s
출력된 결과를 확인해보자. 약 3천만 건의 주문 정보에서 최소 지지도 0.01를 넘는 약 4만 8천건의 연관 규칙을 찾아 내었고, 연관 규칙을 만들어 내는 데 걸린 시간은 6분 24초가 걸렸다는 것을 알 수 있다.
찾은 결과를 출력해 보자.
# 품목 ID를 보기 좋게 하기 위해서 품목 이름으로 바꿔준다.
item_name = pd.read_csv(path + '/products.csv')
item_name = item_name.rename(columns={'product_id':'item_id', 'product_name':'item_name'})
rules_final = merge_item_name(rules, item_name).sort_values('lift', ascending=False)
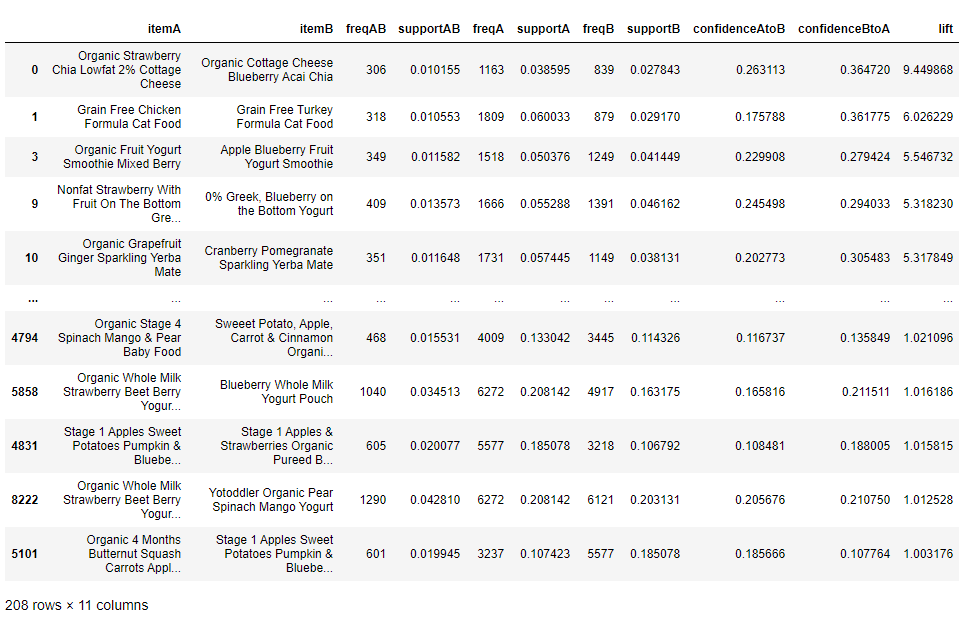
display(rules_final)
연관 규칙 결과 테이블
출력된 연관 규칙 테이블을 보면 다소 복잡해 보일 수 있으나, 맨 마지막 열의 향상도(lift)를 보면 품목 간의 관계를 확인 할 수 있다.
lift = 1, 품목간의 관계 없다. *예: 우연히, 같이 사게되는 경우
lift > 1, 품목간의 긍정적인 관계가 있다. *예: 같이 사는 경우
lift < 1, 품목간의 부정적인 관계가 있다. *예: 같이 사지 않는 경우
출력된 향상도를 이용하여 결과를 분석해보자.
먼저, 품목 간의 긍정적인 관계인 향상도가 1 보다 큰 결과를 살펴 보자.
코티지 치즈는 블루베리 아사이 맛과 딸기 치아 맛을 같이 구매한다.
고양이 먹이는 치킨 맛과 칠면조 맛을 같이 구매한다.
요거트는 믹스 베리 맛과 사과 블루베리 맛을 같이 구매한다.
위 결과를 토대로 생각해 보면, 대부분 구입한 한 가지 품목에 대해서 다른 맛을 내는 같은 품목을 같이 구입한다는 것을 알 수 있다.
다음으로, 품목 간의 부정적인 관계인 향상도가 1보다 작은 결과를 보자.
유기농 바나나를 사는 경우 일반 바나나는 사지 않는다.
일반 품종의 아보카도를 구입한 경우 하스 아보카도를 구입하지 않는다.
유기농 딸기를 사는 경우 일반 딸기를 사지 않는다.
이번 결과에서는 구입한 한 가지 품목에 대해서 다른 생산과정 혹은 영양구성의 같은 품목은 같이 구입하지 않는다는 것을 알 수 있다.
이전 포스팅에서 언급했듯이, 단순히 나열된 구매 정보만으로는 확인 할 수 없었던 규칙들을 연관 분석을 통해서 알아 낼 수 있게 되었다. 이러한 정보를 바탕으로 고객들에게 제품을 추천 한다거나 상품의 배열을 바꿔 줄 수 있다면 상품 판매에 의미 있는 결과를 얻을 수 있을 거라 생각한다.
이 노래 가사는 2014년 한국 힙합씬 최대의 이슈 트랙중 하나인 일리네어 레코즈의 연결고리 라는 노래 중 메인 플로우의 한 부분이다.
이 노래의 가사 절반 이상이 저 가사로 가득 차있다. 아마도 연관관계가 없어보이는 너와 나를 이어주는 공감대을 찾고 싶어 했던 것 아니였을까 싶다.
이렇듯, 우리는 언제나 연관관계가 없어보이는 것들 사이에서 접점인 연결고리를 찾고 싶어 한다. 주변 사람들에 대해서도 물론이고 자신이 가지고 있는 물건, 취향들 심지어는 행동까지 연관지어 생각한다.
특히나, 최근에는 디지털 뉴딜이니 데이터 댐이니 하는 이슈로 인해서 데이터에 관심이 집중되고 있고, 이러한 영향으로 자신이 가지고 있는 다양한 데이터 속에서 연관된 규칙을 찾고자하는 사람들이 늘어나고 있다.
게다가 요즘 핫한 AI라는 것이 무의미해 보이는 데이터 속에서 의미 있는 패턴(연관규칙)을 저절로 찾아 준다고 하니, 꼭 한번 해보고 싶을 것이다.
그렇다면, 연관 분석(Association Analysis)이 무엇인지 개념부터 사용법까지 하나씩 알아보자.
경영학에서는 장바구니 분석(Market Basket Analysis)으로 알려진 연관분석은 ‘전체 영역에서 서로 다른 두 아이템 집합이 어떠한 조건과 반응의 형태(if – then)로 발생하는가’ 를 일련의 규칙으로 생성하는 방법(혹은 알고리즘)이다.
예를 들어 ‘아메리카노를 마시는 손님중 10%가 브라우니를 먹는다.’라고 하거나 ‘샌드위치를 먹는 고객의 30%가 탄산수를 함께 마신다.’ 과 같은 식의 결론을 내는 것이다.
이런 규칙성을 많이 사용하는 분야는 대표적으로 판매업이 있다. 고객이 어떤 상품을 고르면 그 상품을 구매한 다른 고객들이 선택한 다른 상품들을 제안해 준다던지 하는 컨텐츠 기반 추천의 기본이 되는 것이다.
그럼 이제, 이러한 연관 분석을 하기 위해 사용되는 데이터부터 살펴보자, 동네 카페 매출이력(transaction)이 다음과 같이 주어졌다고 생각해보자.
거래번호
품목
1154
아메리카노
아이스 카페모카
허니브래드
블루베리 치즈케이크
치즈 케이크
1155
카라멜 마키아또
브라우니
크림치즈 베이글
1156
아메리카노
탄산수
크랜베리 치킨 샌드위치
1157
아메리카노
카라멜 마끼아또
허니 브래드
위 데이터에서 각 고객이 구입한 품목들을 확인 할 수 있는데, 데이터의 연관규칙을 찾기 위해서는 다음과 같이 희소행렬(Sparse Matrix)로 나타내 주면 좋다.
아메리카노
아이스 카페모카
카라멜 마키아또
탄산수
블루베리 치즈 케이크
치즈 케이크
허니 브래드
브라우니
크림 치즈 베이글
크랜베리 치킨 샌드위치
1154
1
1
0
0
1
1
1
0
0
0
1155
0
0
1
0
0
0
0
1
1
0
1156
1
0
0
1
0
0
0
0
0
1
1157
1
0
1
0
0
0
1
0
0
0
이제 연관규칙을 찾을 준비는 되었다. 조건과 반응 형태로 규칙을 만들면 되는데, 다음과 같이 규칙을 만들 수 있다.
아메리카노를 마시는 사람은 아이스 카페모카도 마신다.
아메리카노를 마시는 사람은 치즈케이크도 먹는다.
아메리카노를 마시는 사람은 허니 브래드도 먹는다.
아메리카노를 마시는 ….
“어?! 뭔가 이상하게 생각 했던 것과는 다르다. 뭔가 그럴듯하게 맞아 떨어지는 규칙은 아니네?” 라고 생각 들것이다.
그 생각이 맞다. 이런식으로 규칙을 만든다면, 주어진 데이터에서 무수히 많은 규칙을 만들어 낼 수 있다. 우리는 이 많은 규칙들 가운데서도 좋은 규칙을 찾아 내는 방법을 알아야 한다.
그렇다면, 좋은 규칙은 어떻게 찾을까?
좋은 규칙을 판단하기 위해서 규칙의 효용성을 나타내는 지표는 지지도(Support)와 신뢰도(Confidence) 그리고 향상도(Lift)이다. 이 3가지 지표를 모두 반영해 규칙의 효용성을 판단하고 좋은 규칙을 선택해야 한다.
이 3가지 지표를 구하는 방법은 다음과 같다.
지지도(Support)
전체 거래 중 품목 A와 품목 B를 동시에 포함하는 거래의 비율로 정의한다.
지지도 공식
신뢰도(Confidence)
품목 A를 포함한 거래 중에서 품목 A와 품목 B가 같이 포함될 활률이다. 연관성의 정도를 파악할 수 있다.
신뢰도 공식
향상도(Lift)
A가 구매되지 않았을 때 품목 B의 구매확률에 비해 A가 구매됐을 때 품목 B의 구매활률의 증가 비(Rate)이다. 연관규칙 A -> B는 품목 A와 품목 B의 구매가 서로 관련이 없는 경우에 향상도가 1이 된다.
향상도 공식
이제 좋은 규칙을 고르는 법도 알았으니 실제로 제대로 된 규칙을 찾아 보자.
가능한 모든 경우의 수를 탐색하여 지지도, 신뢰도, 향상도가 높은 규칙을 찾을 수 있다면 가장 이상적일 것이다. 데이터가 작으면 가능할지도 모르겠지만, 데이터가 증가 하면 할수록 계산에 드는 속도도 기하급수적으로 늘어나게 된다.
(알고리즘의 데이터 증가에 대한 복잡도는 n^2이다.)
이러한 이유로 자주 발생하는 아이템에 대해서 빈발 집합(Frequent item sets)을 만들고 이 집합만 고려하는 규칙을 만드는 것이 효율적이다.
예를들어 품목 탄산수의 지지도, 즉 P(탄산수)가 0.1로 나타났다고 보면, 탄산수를 포함한 품목의 지지도는 아무리 높아도 0.1을 넘지 못할 것이다. 탄산수가 단독으로 등장할 확률인 P(탄산수)는 아무리 크게 나와도 P(탄산수, 아메리카노)를 넘지 못 할 것이기 때문이다. 이때 {탄산수, 아메리카노}는 {탄산수}, {아메리카노}의 초월집합(Super set)이라고 한다.
임의의 품목 집합의 지지도가 일정 기준을 넘지 못한다면 해당 집합의 초월 집합의 지지도는 그 기준보다 무조건 더 작을 것이기 때문에 유용한 규칙으로 선택 될 수 없다. 이처럼 최소 지지도 요건을 만족하지 못하는 품목 집합의 규칙을 애당초 제외하면 계산의 효율성을 높일 수 있다.
빈발관계 탐색
그럼 다시 연관 규칙분석을 수행해보자. 최소 지지도 요건을 0.3으로 설정했다고 하자. 그럼 각 품목의 지지도는 아메리카노(0.75), 아이스 카페모카(0.25), 카라멜 마키아또(0.5), 탄산수(0.25), 블루베리 치즈 케이크(0.25), 치즈 케이크(0.25), 허니 브래드(0.5), 브라우니(0.25), 크림 치즈 베이글(0.25), 크랜베리 치킨 샌드위치(0.25)로 나타낼 수 있다.
여기서 최소 지지도를 만족하지 못하는 것들을 제외하여 2개짜리 품목 집합을 생성하면, 다음과 같다.
아메리카노
카라멜 마키아또
허니 브래드
아메리카노
0
0.25
0.5
카라멜 마키아또
0
0.25
허니 브래드
0
여기서도 마찬가지로 품목 {아메리카노, 카라멜 마키아또}와 {카라멜 마키아또, 허니 브래드}는 최소 지지도 0.3을 만족하지 못하였으니 제외 한다. 이런 방식으로 더 이상 최소 지지를 만족하지 못하는 집합이 없을 때까지 품목 집합의 크기를 1씩 증가 시켜가면서 반복 수행 한다.
이러한 방식으로 구한 동네 카페 매출이력 4건을 토대로 가장 좋은(강한) 연관 규칙은 “아메리카노를 마시는 사람은 허니 브래드도 동시에 먹는다.”가 되는 셈이다.
조건절
결과절
지지도
신뢰도
향상도
아메리카노
허니 브래드
0.5
0.67
1.33
여기까지, 연관관계 분석 방법에 대해서 알아보았고, 연관 분석을 통해서 그냥 눈으로만 봐서는 알 수 없었던 거래 데이터에서 규칙을 찾아 낼 수 있었다.
이 외에도 연관 분석 방법은 거래 데이터 뿐만 아니라 순차적이고 반복적으로 발생하는 대부분의 데이터에 적용 할 수 있다.
운영하는 홈페이지에서 어떤 순서로 컨텐츠를 클릭 하였는가?
특정 직무의 사람들은 어떤 순서로 일을 하는가?
특정 문서에 출현한 단어들이 어떤 유의미한 의미로 요약 될 수 있는가?
위의 예 처럼 생각해 볼 수록 많은 응용점들이 있을 거라 생각한다. 한번 자신이 가지고 있는 데이터를 이용하여 각 특성들이 어떤 연결고리가 있는지 분석해 볼 수 있을 것 같다.
2006년에 개봉한 ‘벤 스틸러’ 주연의 ‘영화 박물관이 살아있다.’는 박물관에서 경비일을 맡게 된 주인공이 밤마다 전시된 인형들이 살아 움직이는 것을 보게 되면서 겪게 되는 사건을 담은 코미디 영화이다.
영화에 나오는 것처럼 박물관에 전시되어 있는 인형들이 실제 생명체처럼 지능을 가지고 움직이는 것은 사실 말도 안되는 일이다. 그렇지만 이런 말도 안되는 일들이 이제는 실제로 일어나려고 하고 있다. 그것이 바로 자율 사물이다.
“사물 인터넷을 뛰어 넘어 사물이 자율적인 지능을 갖는다.”
자율 사물(Internet Of Autonomous Things, IoAT)이란, 사물에 인터넷이 연결되어 정보를 수집하고 교환하는 개념의 사물 인터넷(Internet of Things, IoT)에 AI가 탑제되면서 사물이 자율성을 가지고 움직이게 되는 것을 말한다.
Bring AI to device everywhere
사물 인터넷에 대한 사례로는, 최근 몇 년 사이에 새로 만들어지는 가전 제품들을 생각해 볼 수 있다. 냉장고 내부에 카메라와 각종 센서들이 부착되어 내부를 들여다 보지 않아도 냉장고에 무엇이 있고 상태가 어떤지 알 수 있다. 그리고 에어컨이나 보일러의 경우 온도 조절 기능을 스마트폰을 이용하여 원격으로 사용 할 수 있도록 되어 있어서 굳이 제품별 리모콘을 사용하지 않아도 스마트폰 하나로 모두 제어 가능하다.
이제는 대부분의 가전이 스마트폰 하나로 제어가 가능하다고 볼 수 있다. 그리고 이러한 인터넷이 연결된 사물들, 사물 인터넷(IoT)에 AI까지 탑제 되어 자율성까지 갖게 된 것이 자율 사물이다.
앞서 언급한 IoT가 적용된 사례에 AI를 적용해 보자.
냉장고 내부를 들여다 보는 각종 센서들은 보관된 음식들의 상태를 보고 적정 온도로 설정 하고 음식들을 더 오래 신선도를 유지 하도록 스스로 조절한다. 에어컨이나 보일러의 경우 사람이 사용하는 시간이나 사용성을 학습하여 사람이 신경쓰지 않아도 필요한 때에 적절히 동작한다.
“사물이 자율성을 갖고 협업하기 시작했다.”
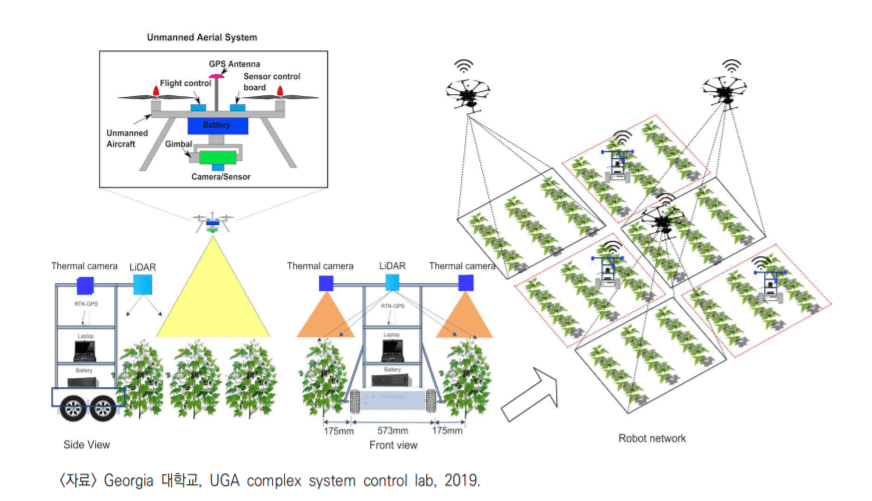
각각의 사물이 자율성을 갖기 시작하면서, 자율 사물들 간의 협업도 가능해지기 시작했다. 실제로, 2019년 미국 Georgia 대학교에서는 자율 사물들 간의 협업을 이용하여 무인 농업을 연구하고 있다고 발표 했다.
미국 NRI 프로젝트
아직은 연구 단계이긴 하지만 상용화 되어 농업에 적용 된다면, 사람은 더 이상 농사를 짓기 위해 육체적인 노동을 하지 않아도 수확물을 얻을 수 있게 된다.
급격한 AI 기술 발전에 힘입어 사물의 자율성은 계속해서 강화 될 것으로 보이며, 농업 뿐만 아니라 각종 제조, 물류, 건설 등의 산업에 적용 될 것으로 보인다.
“앞으로의 자율 사물의 미래 산업 전망은?”
자율 사물은 2016년부터 가트너의 미래 산업 전망에 사물인터넷과 기계 학습이라는 형태로 소개 되기 시작하다가 2019년부터는 10대 전략 기술 트랜드에 포함되어, 향후 5년 내 자율 사물 시대가 올 것이라고 전망되고 있다.
또한, 글로벌 시장 조사 기관인 MarketsandMarkets에서는 IoT용 AI 시장이 2019년 51억 달러에서, 2024년에는 162억 달러 규모까지 확대 될 것으로 전망하고 있다.
Attractive market opportunities in the AI in IoT market
자율 사물의 핵심 기반은 AI이다. 현재 AI는 인간이 수행하던 많은 업무를 자동화하는 데 기여하고 있다. 하지만 앞으로는 자동화의 수준을 넘어 사물에 탑재되어 동작하는 온디바이스(on-device) 방식으로 진화되어 업무 절차와 판단 기준을 학습함으로써 인간의 개입 없이 동작하는 자율화를 실현해 나갈 것이다.
현재의 AI 기술은 비록 제한된 범위 내에서만 자율적으로 판단, 의사결정을 할 수 있는 수준에 도달하고 있지만, 앞으로 AI 관련 기술의 꾸준한 투자와 연구 개발로 인해서 더 높은 수준의 자율 사물을 확산시킬으로 전망 된다. 이는 많은 산업군의 업무 생태계의 변화를 의미 한다고 생각되며, 앞으로 어떤 새로운 가치를 발견하고, 적응해 나갈 것인가를 고민해 봐야 할 것 같다.
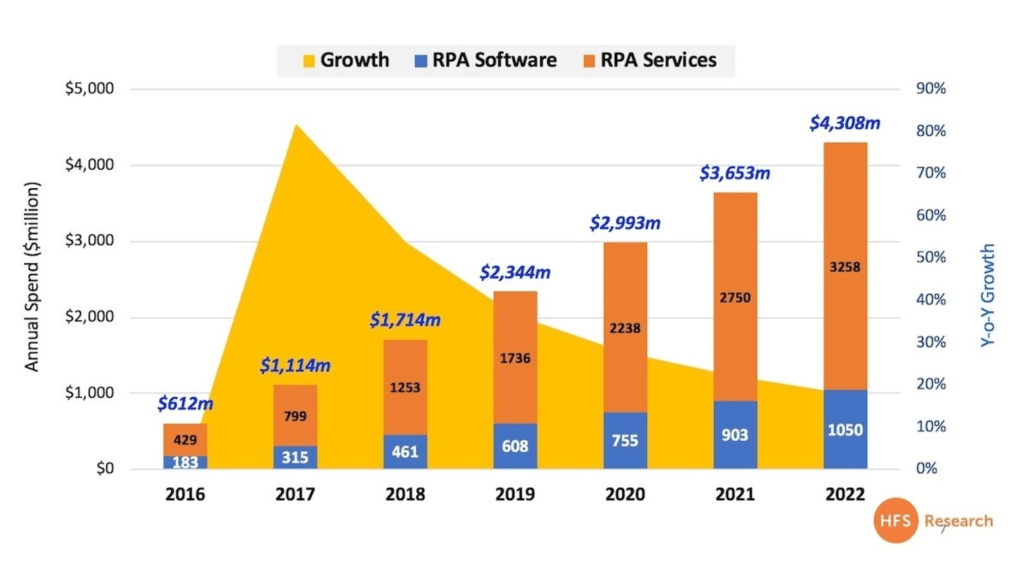
RPA는 Robotic Process Automation의 약자로, 사람이 하는 단순 반복 업무를 로봇을 통해서 자동화하는 것을 의미한다. 여기서 로봇이라 하면, 공장 생산 라인의 실체적 기계가 생각이 들겠지만, RPA는 Software로 구현된 전산업무를 위한 로봇이다.
개념적으로 그리 어려운 것은 아니지만, 최근 몇 년간 엄청나게 가파른 성장을 보여주고 있다. HFS 시장 조사기관에 따르면 RPA 시장 규모는 2016년 약 6억 1,000만 달러를 기록한 이래로 매년 평균 40% 성장하여 2022년에는 약 43억 달러 규모로 성장할 것으로 보여진다.
RPA Service and Software Market 2016-2022
“무엇 때문에 이렇게 성장하는 것 일까?“
그 동안 적용이 어려웠던 일선 업무 환경까지 자동화가 확장 된 것이 크다고 볼 수 있다. 일선 업무 환경(Front Office)은 사람이 판단해야 하는 경우가 많아 정형화가 어렵기 때문에 자동화를 적용하기엔 많은 어려움이 있었다. 대부분 일선 업무들의 자동화라는 것들은 지원 업무(Back Office)를 통해서 처리 결과를 받아 처리하는 형태로 업무가 이루어 지고 있었다.
예를들어, 인바운드 고객 서비스를 처리 한다고 해보자. 고객 서비스 관리 채널을 통해 고객 서비스 내용을 접수한 담당자는 서비스를 요청한 고객에 대한 정보를 내부에서 관리하는 고객 관계 관리(CRM: Customer Relationship Management) 시스템에서 조회/확인할 것이다. 그리고 확인된 고객정보를 기준으로 서비스 내용을 해결하고 최종 처리 결과에 대해서 고객에게 전달하고 같은 내용을 내부 서비스 관리 시스템에 등록할 것이다.
위 예시에서 언급된 CRM 시스템은 일선 업무에서 수작업으로 관리하던 고객 정보를 지원 업무를 통해 관리 정보를 정형화 하고 프로세스 체계를 만들어 고객정보 관리를 자동화 시킨 시스템이다.
즉, RPA 이전의 자동화라는 것은 일선 업무에서 필요한 내용을 지원 업무로부터 자동화 서비스 형태로 제공 받은 것을 말한다. 하지만 RPA가 등장한 이후에는 일선 업무 담당자가 자신이 하는 일에 대한 일련의 과정을 프로세스로 정의만 할 수 있으면 지원 업무를 통하지 않고도 많은 부분 자동화 할 수 있게 되었다.
다시 고객 서비스 예시로 돌아가 RPA를 적용해 보자. 일선 업무 담당자가 고객 서비스를 접수하면 그 순간 자동으로 RPA 로봇이 관련 고객 정보를 수집하여 보여 줄 것이다. 고객 서비스를 하는 데 있어서 선제적으로 고객 정보를 파악할 수 있게 되는 것이다. 그리고 고객 서비스 응대 완료 후 고객에게 답변을 보내면 RPA 로봇이 같은 내용을 내부 서비스 관리 시스템에 자동으로 등록해 줄 것이다. 같은 내용을 여러 시스템에 등록하던 업무를 1회만 하게 되어 업무 효율을 높일 수가 있게 된다.
마치 RPA 로봇과 협업을 하여 업무를 처리 한다고 생각할 수 있다.
일선 업무 담당자가 수작업으로 하던 기간계 업무를 RPA 로봇과 협업하여 생산성을 높일 수 있게 된 것이다. 이러한 이유로 대부분의 산업 분야로부터 지대한 관심을 받게 되었고, 그것이 엄청나게 가파른 성장으로 이어진 것이다.
“RPA를 충분히 잘 활용하려면 어떤것들이 준비 되어 있어야 할까? “
도입 초반에는 사람의 판단이 필요없는 단순 반복적인 작업이나, 간단한 조회성 잡무들에 적용을 하게 된다. 가장 가까운 예로 내부 관리 시스템(ERP, Groupware 등)에 로그인을 하거나 받은 메일함에서 특정 메일 데이터를 정리하는 것들이 있다. 이러한 것들만 대체되어도 업무를 수행 하는 데 있어서 많은 도움이 된다. 하지만 시간이 갈 수록, 이러한 부분은 한사람이 처리할 수 있는 일의 양을 늘렸을 뿐, 근본적으로 전체적인 업무를 자동화 하진 못하는 한계가 나타난다.
RPA 도입이 충분한 효과를 내기 위해서는 자신의 하고 있는 일련의 업무를 전체적으로 이해하고 자동화 하기 위한 단위 프로세스를 도출해 내는 능력을 키워야 한다. 그리고 도출된 단위 프로세스들을 지속적으로 자동화 컨텐츠로 준비 해두어야만 RPA를 잘 활용할 수 있게 된다.
“앞으로는 AI와 RPA 결합을 통해 초자동화 시대가 될 것이다.”
현재는 사람의 직관으로 판단해야 하는 부분으로 인해서 모든 업무의 과정을 자동화 프로세스로 만들어 내기 어렵다. 하지만 RPA에 AI가 결합 된다면 사람의 개입을 최소화할 수 있고, 업무 효율을 최대로 끌어 올릴 수 있다.
사람과 로봇이 협업하는 초자동화 시대
이전 포스팅에서 다뤘던 자연어 처리에 대한 내용과 연관지어 생각해 보면, 사람의 말을 알아 듣는 챗봇과 사람이 하던 업무들을 자동으로 처리하는 RPA 로봇의 조합을 생각해 볼 수 있다. 그리고 이러한 생각은 수 년 내에 우리의 일상에서 접할 수 있을 것이라 본다. 로봇과 일상적인 언어(자연어)로 대화하고 자동으로 처리된 결과물을 받아보는, 사람과 로봇이 협업하는 초자동화 시대가 올 것이라고 감히 생각해본다.
최근 인공지능이 실제 비즈니스에 적용되면서 많은 산업의 전반에 영향을 미치고 있다. Statista에 따르면 세계적으로 인공지능에 대한 시장 전망이 2018년 약 95억달러에서 연 평균 43%씩 성장하여 2025년에는 1,186억달러 규모로 이를 것이라고 한다.
Revenues from the artificial intelligence (AI) software market worldwide from 2018 to 2025
AI를 포함한 글로벌 소프트웨어 서비스 전체 시장이 2018년부터 2025년까지 매년 10% 성장하여 3,229억 달러 규모가 될 것이라는 것을 생각해 보면 엄청난 투자와 성장이 이루어지고있다는 것을 알 수 있다.
이런 이유로 사업을 하는 사람이라면 누구나 기업 비즈니스에 어떻게든 하루 빨리 인공지능을 도입하고 싶을 것이다.
“그런데 정말 인공지능을 도입하면 비즈니스의 매출이 성공적으로 올라갈까?” “기존의 소프트웨어 프로그램들로는 할 수 없는 것인가?”
이것에 대해 이야기하기 전에 먼저 기존의 소프트웨어 프로그램들이 어떠했는지 생각해 볼 필요가 있다.
그 동안의 프로그램들은 연속적이지 않고 구분되어진 이산 논리를 가지고 나오는 경우 수들을 공식화하여 만든 것들이다.
우리의 일상생활을 살펴 보자.
아침에 일어나야 하기 때문에 매일 아침 7시가 되면 알람이 울리도록 알람을 맞춘다. 시간은 사실 연속적이지만 그 시간을 시, 분, 초로 이산화 시켜 표기하고 아침 7시라는 경우가 되면 알림이 울리도록 되어 있는 것이다.
이것 저것 분주히 준비한 다음 집을 나서면 엘리베이터를 마주하게 된다. 엘리베이터의 한쪽 벽에 표시된 층수를 누르면 엘리베이터는 해당 층수로 이동한다. 공간 또한 마찬가지로 연속적이지만 층이라는 규격화된 높이로 이산화 시켜 표시하고 눌려진 버튼에 입력된 층의 위치로 이동하는 것이다.
예시에서 알 수 있듯이 이산 논리는 확실하게 구분된다. 어떤 경우에 해당되는지 그렇지 않은 것인지 확실한 선을 긋는 것이다. 이 선들이 조건(Rule)이 되고 조건들을 조합하여 공식을 만든 것이 프로그램이 되는 것이다.
일상에서 쉽게 볼 수 있는 간단한 프로그램들을 예시로 들었지만 사업에 사용되는 프로그램들도 마찬가지다. 단지, 관련 분야의 도메인 전문가가 문제를 해결하기 위해서 좀 더 세분화된 조건(Rule)들을 도출해 냈을 뿐이다.
예를 들어, 어느 과수원에서는 사과를 중량으로만 선별 하고 중량을 나누는 작업을 자동화 시스템으로 개발 한다고 가정해 보자. 먼저, 각 사과들의 중량을 측정할 것이다. 그리고 측정된 중량들을 이산화 된 등급의 조건으로 만들어 준다. 가령 200~350g이면 가정용, 351~400g이면 선물용 , 401g 이상은 제수용으로 등급을 만들어 주면 이 시스템을 통해서 사과들은 3개의 등급으로 구분되게 된다.
이 시스템에서는 사과의 무게가 350g이라면 가정용으로 분류할 것이다. 그리고 351g은 선물용으로 분류가 될 것이다. 그러면 1g 차이로 가정용과 선물용으로 분류 되는데 이 것이 합리적인 것일까? 350g이 351g보다 실제로 선물용으로 가치가 더 있다면?
실제로 사과를 제대로 선별하기 위해서는 중량 외에 빛깔, 형상, 과육 등등 기준들이 더 많이 있어야 한다. 때문에 사과를 좀 더 잘 선별하기 위해서는 ‘사과’라는 여러 속성을 갖는 객체를 만들고 각 속성에 값을 측정하여 입력하고 특정 조건이 만족할 경우 분류 되게 해야 한다.
그럼 다시 질문해 보자. 전 보다 조건이 많아 졌으니 이제는 합리적으로 나눌 수 있는 것일까?
글쎄다. 어디까지나 이산 논리에 대한 조건들이 세분화 된 것일 뿐이지 경계가 불분명한 예외사항은 언제나 발생 하고, 발생한 예외는 결국 사람이 처리해야 한다. 이것이 인공지능 이전의 프로그램 방식들인 것이다.
“그렇다면, 인공지능이 도입된 프로그램 방식은 무엇 일까?”
1(참)과 0(거짓)으로만 나누는 이산적인 방식에서 0~1 사이의 모든 실수로 확장된 것을 의미한다. 다시 말하면 어떤 등급에 속할 가능성으로 나타내는 것이다.
예를 들어, 사과의 중량은 350g이지만 다른 조건들로 인해 이 사과가 선물용으로 적합하다는 가능성이 0.86으로 정의 할 수 있다면 이 사과는 가정용이 아니라 선물용이 되는 것이다. 이처럼 경계선이 명확하지 않은 대상을 다룰 수 있는 것이 인공지능이 도입된 프로그램 방식이다.
이렇게 간단하게 설명하면 신기하게 들릴 수도 있지만 이것은 그 동안 잘 처리하지 못한 불분명한 예외사항을 기계가 효율적으로 나누기 위한 추론 기법일 뿐이다.
사람은 350~351g의 애매한 중량의 사과라면 손으로 만져보고 눈으로 보고 향을 맡아본 뒤 직관적으로 분류했을 것이다. 이렇게 사람이 분류 하던 데이터들을 기계에게 학습시키면, 기계는 데이터에서 패턴을 찾고 그 패턴을 추론로직으로 사용하는 것이다.
결국, 완전한 인공지능이라기 보단 사람의 직관을 흉내낼 수 있어서 사람의 인지적인 부분을 도와 줄 수 있는 형태인 것이다.
그런데 왜 이렇게 사람들이 관심을 갖고 열광하는 것일까?
그 이유는 최근 몇 년 사이 그 흉내내는 수준이 단순 흉내 이상의 가치를 만들고 시작했기 때문이다. 가장 가깝게는 스마트 폰으로 사진을 찍으면 사진을 자동으로 보정하고 분류해준다. 공장에서는 제품의 상태를 사람 보다 더 잘 예측하고, 병원에서는 환자의 영상데이터를 의사보다 더 정확히 분석하고 있다.
인지능력으로는 이미 인간의 수준을 넘어선 것있다.
이런 기능이 물리적인 제약 없이 24시간 365일 쉬지 않고 동작 할 수 있기 때문에 완전한 인공지능이 아님에도 불구하고 비즈니스 매출에 성공적인 상승 가져다 주는 것이다.
“그렇다면, 어떻게 하면 인공지능을 비즈니스에 적용 할 수 있을까?”
인공지능을 비즈니스에 적용하기 위해서는 많은 것들이 필요하지만 꼭 필요한 3가지가 있다.
첫째로 비즈니스에서 해결하고자 하는 문제점을 정확히 알아야 한다. 위에서 설명했듯이 최근의 인공지능은 완전한 인공지능이 아니기 때문에 그저 ‘도입하면 무엇이든 되겠지’라고 생각 하는 순간 실패사례로 남게 된다. 문제점을 잘 파악하기 위해서 비즈니스에 대한 프로세스를 잘 정립하고 프로세스 간의 절차와 관계를 정의하여 해결하려고 하는 문제점을 정확히 이해하고 도출해야 한다.
두번째로, 인공지능이 학습 가능한 데이터로 기존 데이터를 가공하고 수집해야 한다. 인공지능에 대한 환상으로 인해 생긴 오해 중 하나인데, 무작정 데이터가 있다고 해서 바로 인공지능에게 데이터를 학습시킬 수 있는 것이 아니다. 데이터에는 생각지도 못한 많은 노이즈 정보들이 있으며, 현재의 인공지능은 이런 정보까지 분별하지 못 한다. 특히, 데이터가 비정형 데이터라면 전처리 기술을 통해서 정형화 혹은 반정형화 작업을 해주어야 학습에 사용할 수 있다. 때문에 인공지능이 학습 가능한 형태로 데이터를 새롭게 만들어 가야 한다.
마지막으로 오픈소스 소프트웨어를 잘 활용해야 한다. 일반 기업에서 인공지능을 처음부터 개발한다는 것은 불가능에 가깝고, 투자가 가능하더라도 너무 뒤쳐지는 발상이다. 이미 잘 개발된 인공지능에 관련한 오픈소스들이 너무 많다. 국내 최고 기술 회사인 삼성, LG는 물론이고 글로벌 선두 IT 기업인 AMG(Amazon, MS, Google)도 인공지능 만큼은 오픈소스를 활용한다. 우리는 거인의 어깨에 올라탈 필요가 있다. 이미 글로벌 기업들이 자신들의 비즈니스로 검증한 오픈소스를 이용하는 것이 비용을 아끼면서 빠르게 성장할 수 있는 발판이 되는 것이다. 오픈소스에 기존 비즈니스를 잘 녹여낼 수 있다면 손쉽게 인공지능 서비스를 제공할 수 있음과 동시에 글로벌 기업의 인공지능 기술을 같이 공유하게 되는 것이다.
그 동안 공상과학 영화에서나 나오던 인공지능에 대한 것들이 점점 현실로 다가 오고 있다. 아직 사회적 부작용도 많고 완성도에서도 완전한 인공지능은 아니지만 인공지능 시장의 성장와 규제 대응 속도를 가만해 보면 향후 5~10년 안에는 우리 생활 속에 정착할 것으로 보인다. 그 때에 앞서가는 비즈니스를 하고 있으려면, 기존 비즈니스를 인공지능을 통해서 어떤 새로운 가치를 만들어 낼 것인가를 고민하는 것이 중요할 것 같다.