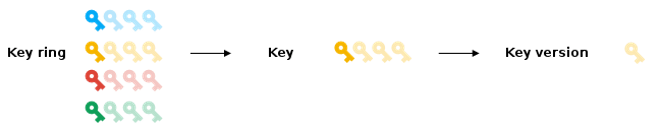WSL(Windows Subsystem for Linux)을 사용하다 보면 user password를 잃어 버리는 경우가 있다. WSL이 아닌 경우 여러가지 복원 절차를 통해야 하지만 WSL인 경우 MS(Microsoft)에서 개발한 리눅스 호환 커털 인터페이스를 제공하기 때문에 간단히 user password를 초기화 할 수 있다.
먼저, 설치된 WSL 버전을 확인 해야 한다. 명령 실행 창에서 ‘CMD’를 실행하고 아래 명령어를 입력하면, 설치된 WSL 버전 정보를 확인 할 수 있다. (여기서는 Ubuntu 1804 Linux를 기준으로 한다.)
c:\> wslconfig /list /all
Windows Subsystem for Linux Distributions:
Ubuntu-18.04 (Default)
설치된 WSL은 Ubuntu-18.04이고, 실행 명령어는 ‘Ubuntu1804’가 된다. (만약, Ubuntu(Default)로 나왔다면 실행 명령어는 ‘Ubuntu’가 된다.)
위에서 확인한 실행 명령어를 가지고 CMD창에서 다음과 같이 Ubuntu 기본 사용자를 root(관리자)로 변경해 준다.
c:\> Ubuntu1804 config --default-user root
이제, WSL Ubuntu를 실행하면 기본사용자가 root로 되어 있기 때문에 root로 로그인 된다. 바로, 대상 user의 password를 변경해 주고 로그아웃 한다.
$ passwd user
Enter new UNIX password: (type password)
Retype new UNIX password: (type password)
$ exit
다시 CMD창으로 돌아와 Ubuntu 기본 사용자를 기존 user로 변경해 준다.
c:\> Ubuntu1804 config --default-user user
이제, 다시 WSL Ubuntu를 실행하여 확인해 보면 password가 변경된 것을 확인 할 수 있다.
Raspbian은 하드웨어 제품인 RPi(Raspberry Pi)와 Linux계열의 OS(Operating System)인 Debian의 합성어로 Raspberry Pi Foundation이 개발한 RPi 전용 OS다.
RPi는 Raspberry Pi Foundation에서 학교와 개발도상국에서 기초 컴퓨터 과학의 교육을 증진시키기 위해 개발한 신용카드 크기의 싱글 보드 컴퓨터이다. 크기가 작고 전력 소비가 5V-2A로 동작하도록 설계되어 있기 때문에 Raspbian은 저전력 ARM CPU에 상당히 최적화되 도록 만들어 졌다.
Raspberry Pi 4 board
Raspbian을 사용하기 위해서는 앞서 설명한 RPi라는 하드웨어가 필요하다.
(Desktop 버전을 사용하여 live Disc를 생성하거나, 가상머신을 이용하여 PC에 설치 할 수도 있다.)
RPi Model B+
RPi 2 Model B
RPi 3 Model B
RPi 4 Model B
SoC
BCM2835
BCM2836
BCM2837
BCM2711
CPU
ARM11 @700MHz
Quad Cortex A7@900MHz
Quad Cortex A53@1.2Ghz
Quad Cortex A72@1.5Ghz
Instruction Set
ARMv6
ARMv7-A
ARMv8-A
ARMv8-A
GPU
250MHz VideoCore IV
250MHz VideoCore IV
400MHz VideoCore IV
500MHz VideoCore VI
RAM
512MB SDRAM
1GB SDRAM
1GB SDRAM
1, 2 or 4 GB
Wireless
None
None
802.11n/Bluetooth 4.0
802.11n/Bluetooth 5.0
Video
HDMI/Composite
HDMI/Composite
HDMI/Composite
2x micro-HDMI/Composite
Audio
HDMI/Headphone
HDMI/Headphone
HDMI/Headphone
HDMI/Headphone
RPi는 그래픽 성능을 띄어나지만 매우 저렴한 가격(약 25~35$)에 구입할 수 있다.
RPi는 OSHW(Open Source Hardware)라서 하드웨어 스팩은 물론이고 전용 OS인 Raspbian역시 오픈소스로 공개 되어 있기 때문에 하드웨어만 구입하면 나머지 사용하는 것에 대해서는 100% 무료로 사용할 수 있다.
RPi 전용 OS인 Rapbian은 Debian을 기반으로 만들어 졌기 때문에 대부분의 주요 명령어는 Debian과 거의 동일하게 사용하는 하다.
APT(Advanced Package Tool)을 통한 소프트웨어 설치 / 업데이트
dpkg(Debian package) 형식의 패키지 소프트웨어 사용
PIXEL(Pi Improved Xwindows Environment, Lightweight)이라는 GUI 기능 제공을 한다. 이를 통해서 데스크탑 환경을 사용할 수 있다. 특히, 데스크탑 환경 중 App Store와 동일한 개념의 PI Store 제공하여 호환되는 Package들을 쉽게 제공 받을 수 있도록 되어 있다.
Raspbian Pi Store
오픈소스 싱글 보드계열 중에서 저렴하고 파워풀한 기능을 제공하고 있어서 가성비가 좋은 제품으로 많은 개발자들에게 사랑 받고 있다.
전 세계적으로 많은 개발자들이 사용하고 있다 보니 많은 관련 개발 커뮤니티들도 분야별로 자연스럽게 형성되고 있다. 초급자라면 관심 있는 분야의 커뮤니티에서 많은 정보(Tip)들을 제공 받을 수 있다. (오픈소스의 장점이 잘 살려진 것 같다.)
import json
import pymssql
#[Tip]json 문자열을 환경변수 파일로 저장하여 사용한다면 서버정보를 노출 하지 않을 수 있다.
json_string =
'{
"host":"Server Address",
"port":1433,
"user":"User ID@Server Name",
"password":"P@ssW0rd",
"database":"Database Name"
}'
json_data = json.load(json_string)
#pymssql 모듈을 이용하여 Connection 생성을 한다.
conn = pymssql.connect(host=json_data['host'], port=json_data['port'], user=json_data['user'], password=json_data['password'], database=json_data['database'])
여기까지 하면 MS-SQL서버에 접근(Connection 완료) 한 것이다. 다음으로 Select query문을 실행하여 데이터를 가져와 보자.
#Connection으로부터 cursor 생성
cursor = conn.cursor()
#Select Query 실행
cursor.execute('select * from [Target Table Name]')
#결과 데이터를 데이터프레임에 저장
df = pd.DataFrame(cursor.fetchall())
#실행이 끝나면 항상 연결 객체를 닫아 주어야 한다.
conn.close()
학습 데이터를 준비 하려다 보면 기존의 데이터를 변형해야 될 때가 있다. 이때 원본 테이블을 가지고 바로 작업을 하게 되면 데이터가 손실 될 수 있다. 백업 데이터가 있다고 하면 그나마 다행이지만 보통 학습에 사용되는 데이터는 양이 많기 때문에 100% 복구하려면 시간이 걸린다. 이런 점들 때문에 될 수 있으면 테이블(혹은 데이터)을 복사해서 사용하면 좋다.
새 테이블을 생성 하면서 데이터 복사
select * into [New Table Name] from [Source Data]
테이블 구조만 복사
select * into [New Table Name] from [Source Table Name] where 1=2
기존 테이블에 데이터만 복사
insert into [Destination Table Name] select * from [Source Table Name]
데이터 과학을 수행할때 주로 사용되는 언어로는 Python과 R이 있다. 그리고 이 2가지 언어를 지원하는 IDE 환경도 많이 나와 있는데, 그 중 협업 환경에서 많이 선호되는 Jupyterhub 사용에 대해서 알아보겠다.
Jupyterhub은 Project Jupyter라는 비영리 단체에서 개발한 오픈소스 프로젝트다. BSD라이선스를 따르고 있어서 누구나 100% 무료로 사용할 수 있다.
Jupyterhub는 특정 사용자 그룹별로 Jupyter Notebook(이하 Notebook)이라는 가상 개발 환경을 제공한다. 데이터 과학을 수행하는 사용자는 Notebook이라는 가상 개발 환경안에서 업무를 수행하면 된다. 즉, Jupyterhub는 여러 Notebook들을 공유하는 서버인 것이다. 때문에 사용자는 공유 서버를 통해서 자신이 원하는 Notebook 가상 환경 및 리소스를 제공받을 수 있기 때문에 설치 및 유지 관리 작업에 부담을주지 않는다. 또한 특정 사용자 혹은 그룹별로 별도의 가상환경을 구성할 수 있기 때문에 시스템 관리가 용이하다.
Jupyterhub는 2가지 배포본을 제공되고 있는데 첫 번째는 가상머신 환경에 설치하는 배포본이고 두 번째는 Serverless 환경인 Kubernetes에 설치하는 배포본이다.
클라우드 상에서 운용하기에는 Scale Set을 자유롭게 확장 및 유지관리 할 수 있는 Kubernetes(Serverless framework)환경이 좋기 때문에 가상머신 설치방법은 건너띄고 Jupyterhub를 Kubernetes에 설치 및 구성하는 방법알 알아 보겠다.
참고로, 여기에서 사용된 Kubernetes는 Azure에서 제공하는 AKS(Azure Kubernetes Service)를 이용하였다.
Jupyterhub를 Azure Kubernetes에 설치하기
먼저, Jupyterhub를 설치할 AKS 클러스터에 대한 크리덴셜을 가져오고 최근 환경으로 설정한다.
RESOURCENAME = 'Jupyter'
CLUSTERNAME = 'Jupyterhub'
az aks get-credentials --resource-group=$RESOURCENAME --name=$CLUSTERNAME
kubectl config set-cluster $ClusterName
Jupyterhub를 바로 설치하기 전 jupyterhub를 환경을 구성할 내용을 준비해야 한다.
Jupyterhub 사전 준비작업
Kubernetes는 Serverless 환경이기 때문에 작업한 파일을 영구적으로 보존할 스토리지 볼륨이 필요하다. 다음과 같이 Storage Class를 만들어 준다.
소프트웨어를 잘 만들기 위해서 많은 디자인 패턴들이 사용되는데, 그중에서 DI(Dependency Injection, 의존성 주입)에 대한 개념과 .NET MVC에서 많이 사용되는 DI Framework들 중 하나인 Ninject(Open Source Project)에 대해서 알아보겠다.
DI(Dependency Injection) 란?
프로그래밍에서 사용되는 객체들 사이의 의존관계를 소스코드가 아닌 외부 설정파일 등을 통해 정의하게 하는 디자인 패턴이다. 개발자는 각 객체의 의존관계를 일일이 소스코드에 작성할 필요 없이 설정파일에 의존관계가 필요하다는 정보만 된다. 그러면 객체들이 생성될때, 외부로부터 의존관계를 주입 받아 관계가 설정 된다.
DI를 적용하면, 의존관계 설정이 컴파일시 고정 되는 것이 아니라 실행시 설정파일을 통해 이루어져 모듈간의 결합도(Coupling)을 낮출 수 있다. 결합도가 낮아지면, 코드의 재사용성이 높아져서 모듈을 여러 곳에서 수정 없이 사용할 수 있게 되고, 모의 객체를 구성하기 쉬워지기 때문에 단위 테스트에 용이해 진다.
이제, .NET에서 MVC 프로젝트를 만들때 DI를 구현하기 위해 가장 많이 사용하는 Open Source인 Ninject에 대해서 알아보자.
이제 의존성 주입을 위한 IoC 설정과, 의존관계 설정(bind)작업을 모두 하였으니 Controller에서 사용해보자.
public class CommonStoreController : Controller
{
public CommonStoreController(ICommonStore common)
{
this.commonStore = common;
}
private ICommonStore commonStore;
public int GetItemCount(string id)
{
return commonStore.Add(id);
}
}
Design Pattern 중 DI(Dependency Injection, 의존성 주입)이라는 패턴에은 표준 프로그래밍을 할 때 중요한 요소이긴하지만 무조건 사용해야 하는 것은 아니다. 간단한 프로그램이나 객체간의 결합이 명확하여 구분하지 않아도 되는 경우 굳이 프로젝트를 무겁게(?) 만들 필요없다.
데브옵스(DevOps)는 소프트웨어의 개발(Development)과 운영(Operations)의 합성어로서, 소프트웨어 개발자와 정보기술 전문가 간의 소통, 협업 및 통합을 강조하는 개발 환경이나 문화를 말한다.
주로 아래 그림과 같이 개발과 운영간의 연속적인 사이클로 설명할 수 있다.
이를 통해서 얻는 장점은 다음과 같다.
신속한 제공
릴리스의 빈도와 속도를 개선하여 제품을 더 빠르게 혁신하고 향상할 수 있다. 새로운 기능의 릴리스와 버그 수정 속도가 빨라질수록 고객의 요구에 더 빠르게 대응할 수 있다.
안정성
최종 사용자에게 지속적으로 긍정적인 경험을 제공하는 한편 더욱 빠르게 안정적으로 제공할 수 있도록, 애플리케이션 업데이트와 인프라 변경의 품질을 보장할 수 있다.
협업 강화
개발자와 운영 팀은 긴밀하게 협력하고, 많은 책임을 공유할 수 있도록, 워크플로를 결합한다. 이를 통해 비효율성을 줄이고 시간을 절약할 할 수 있다.
보안
제어를 유지하고 규정을 준수하면서 신속하게 진행할 수 있다. 자동화된 규정 준수 정책, 세분화된 제어 및 구성 관리 기술을 사용할 수 있다.
그럼, DevOps를 실현하기 위해서는 어떻게 해야 하는가?
DevOps를 실현하기 위해서는 CI(Continuous Integration)/CD(Continuous Deployment(Delivery))라는 2가지 작업을 해야 한다.
CI(Continuous Integration)은 Development에 속하는 작업으로 지속적으로 프로젝트의 요구사항을 추적하며, 개발된 코드를 테스트 및 빌드를 수행한다.
프로젝트 기획 + 요구사항 추적
프로젝트 시작
기획(프로젝트 방법론 채택)
작업관리(Backlog 관리)
진행상황 추적
개발 + 테스트
코드작성
단위 테스트
소스제어
빌드
빌드 확인
CD(Continuous Deployment(Delivery))는 Operations에 속하는 작업으로 CI가 완료되어 빌드된 소스를 통합 테스트(개발, QA, Staging)를 거쳐 배포를 하며, 배포된 사항들을 지속적으로 모니터링하고 프로젝트 요구사항에 피드백하는 작업을 수행한다.
빌드 + 배포
자동화된 기능 테스트
통합 테스트 환경(Dev)
사전 제작 환경 (QA, Load testing)
스테이징 환경(Staging)
모니터링 + 피드백
모니터링
피드백
이제, DevOps를 하기위한 구체적인 작업을 알았으니, 실제 구성을 하도록 하는 제품들에 대해서 알아보자.
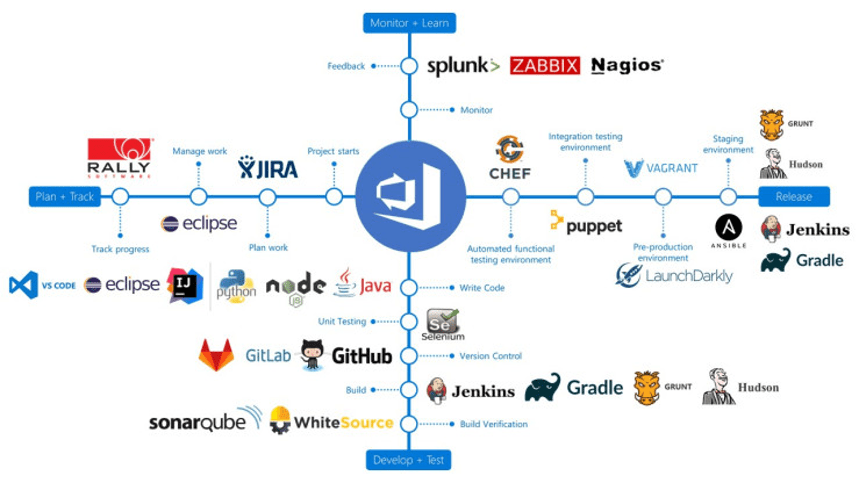
Azure DevOps vs Other Software
DevOps를 하기 위한 솔루션들은 이미 시중에 엄청나게 나와 있으며, 대게 오픈소스 형태로 많이 제공되고 있어서 바로 가져다 사용할 수 있다.
위 그림에서 볼 수 있듯이 DevOps의 각 단계에 맞추어서 원하는 (특화된)제품을 선택하여 사용하면 된다.
모든 단계를 빠짐 없이 구현한다고 가정하여, 예를 들면 다음과 같이 DevOps가 구현 될 수 있다.
Slack으로 요구사항 관리를 하고
Git으로 소스코드 관리를 하고
Maven으로 빌드를 하고
JUnit으로 테스트하고
Jenkins로 Docker에 배포하고
Kubernetes로 운영하며
Splunk로 모니터링 한다.
그런데 이런 경우, 벌써 필요한 제품에 8개나 된다. 프로젝트에 참여하는 모든인원이 이 제품들에 대해서 이해하고 사용하기 어려우며, 각 제품에대한 담당자들있어야 제대로 운영 될 수 있을 것이다. 게다가, 각기 다른 제품이라 다음 단계로 넘어가기 위한 추가적인 관리를 해야할 것이다.
이렇게 되면, 규모가 작은 곳에서는 몇가지 단계를 건너띄고 관리를 하게 되는데 이런 부분에서 예외사항이 생기기 시작하고, 결국 프로젝트 끝에서는 DevOps를 거의하지 못하는 상황이 생길 수 도있다.
반면, Azure DevOps는 하나의 DevOps 관리 솔루션을 제공한다. 때문에 Azure DevOps 하나만 사용해도 모든 절차를 구성 할 수 있다. 그리고 만약, 기존에 사용하던 제품이 있다 하더라도 아래 그림과 같이 3rd-party를 마이그레이션 혹은 연동 설정 할 수 있도록 하기 때문에 Azure DevOps 제품안에서 하나로 통합 관리 할 수 있다.
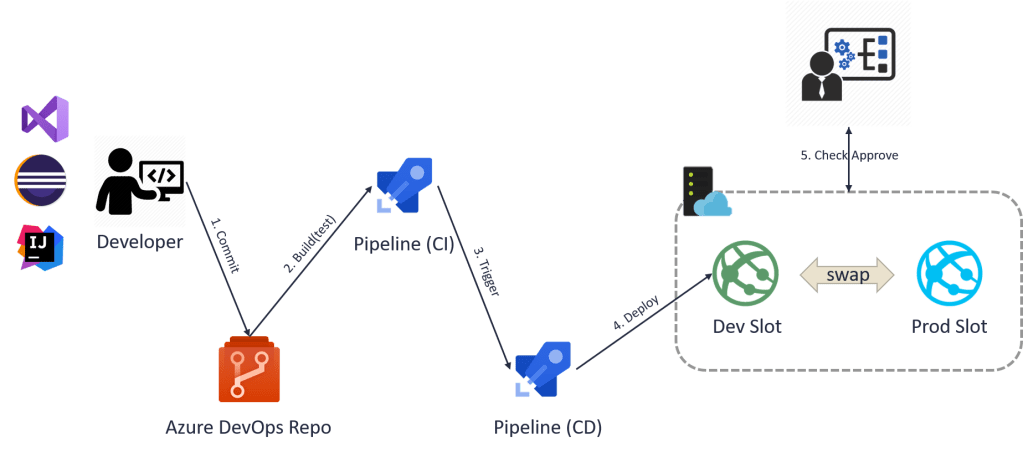
마지막으로, Azure DevOps를 사용하는 간단한 시나리오에 대해서 알아보자.
Azure DevOps에서는 파이프라인이라는 형태로 CI/CD를 구성하도록 되어 있으며, 각 단계 구성은 아래 그림과 같다.
Project (Agile) Board를 통해서 프로젝트 요구사항 추적 관리를 하고
Repo에서 각 Agile Board Task에 대한 소스코드 관리를 하고
소스가 커밋이 되면 CI 파이프라인을 통해 빌드 + 테스트를 수행하고
CI가 완료되면 Trigger 형태로 CD 파이프라인을 실행하고
CD 파이프라인을 통해 통합 테스트 + 배포를 하고
(옵션)담당자에게 최종 승인을 받고
운영 적용 및 모니터링을 한다.
Azure DevOps 이 외의 제품을 사용 했을 때와 단계는 거의 동일 하지만, 여기서 주목 할 점은 Azure DevOps 단일 제품에서 모두 제공 받고 구성 할 수 있다는 것이다.
(**여기서 다 설명 못한 부분이지만 CI/CD 과정 중에 Function(Trigger) 형태로 여러 기능들을 다양하게 엮을 수도 있다. 예를 들어 6번)
각각의 솔루션 전문가들이 있어서 운영한다면 문제가 없겠지만, DevOps를 처음 도입한다던가 규모가 작아 축소 운영을 해야하는 상황이라면 고려해 볼 수 있을 것 같다.
암호화 Key의 정확한 제어 엑세스 관리를 위해 Key ring, Key, Key version이라는 계층 구조를 가지고 있다.
Key ring
조직화 목적을 위해 키를 그룹화 한 것 이다.
Key는 Key를 포함하는 Key ring에서 권한을 상속받는다. 연관된 권한을 가진 Key를 Key ring으로 그룹화하면 각 키를 개벽적으로 작업을 수행할 필요 없이 Key ring 수준에서 해당 키를 대상으로 권한을 부여, 취소, 수정 할 수 있다.
Key
AES-256키를 GCM(Galois Counter Mode)로 사용한다.
특정한 용도를 위해 사용되는 암호화 키를 나타내는 명명된 객체이다.
시간이 경과 되어 새로운 키 버전이 생성되면 키자료인 암호화에 사용되는 실제 비트가 변경될 수 있음.
Key version
일정한 시점에 하나의 키와 관련된 키 자료를 나타낸다.
임의의 여러 버전이 존재 할 수 있으며 버전은 최소 하나 이상 있어야 한다.
Azure Key Vault
암호화 표준은 RSA-OAEP를 사용한다.
비밀정보를 중앙 위치에 보관하고 보안 액세스, 권한 제어 및 액세스 로깅을 제공한다.
비밀 정보를 접근하고 사용하려면 Key Vault에 인증 해야하며, Key Vault 인증은 AAD(Azure Active Directory)에서 인증 지원하는 ID(App Client ID)를 통해 인증 받을 수 있다.
접근 정책은 ‘작업’을 기반으로 한다. – Application 별로 비밀 값 읽기, 비밀 이름 나열, 비밀 만들기 등의 권한을 부여한다.
제공되는 보안 컨트롤
Data Protect – TDE(투명한 데이터 암호화)와 Azure Key Vault를 통합하면 TDE 보호기라는 고객 관리형 비대칭 키를 사용하여 DEK(데이터베이스 암호화 키)를 암호화할 수 있습니다.
Network ACL – 가상 네트워크 서비스 End-Point를 사용하면 지정된 가상 네트워크에 대한 액세스를 제한할 수 있습니다.
정리하면, AWS, GCP의 KMS는 암호화 키를 안전하게 저장 하는 것과 키를 암호화하는 작업(암호화와 복호화)에 초점이 맞춰져 있다고 볼 수 있고, 반면, Azure Key Vault는 백엔드에서는 키 암호화 작업을 통해 비밀을 저장하는 등, KMS와 유사하게 기능들을 제공하지만 그 외 추가 적인 관리 기능들을 제공하기 때문에 비밀 관리 솔루션을 제공한다고 볼 수 있다.